поисковая система с интеллектом человека

Нигма – это интеллектуальная поисковая система, созданная нашими соотечественниками Владимиром Чернышевым и Виктором Лавроненко.
Начало этому положила их встреча в 2004 году, а затем плодотворное сотрудничество по созданию качественно нового проекта для Рунета.
Несмотря на то что сервис использует при выдаче ресурсы самых популярных поисковиков, у нее самой в загашнике находится множество интересных задумок.
Но давайте не будем уходить в дебри, а сразу перейдем к знакомству с сервисом продвинутого поиска.

Об этом более подробно ниже по тексту…
Как появился поиск от Nigma, особенности работы
Данная поисковая система производит поиск не только по собственному индексу, но и по индексам самых разнообразных своих «коллег» – Яндекс, Yahoo, Rambler, Bing.
Что касается Google, в программе разработки алгоритмов для Нигмы участвовал в 2007 году профессор Стэндфордского университета Гектор Гарсия-Молина, являвшийся в свое время научным руководителем основателей этого самого популярного на сегодняшний день поисковика.

По состоянию на февраль 2009 года у Нигмы в сумме индексов с привлекаемыми поисковиками было более 7 миллиардов документов.
Вообще, это первая кластеризующая система российского интернета, но давайте разберемся, что это за зверь такой.
Когда вы вводите свой запрос в поисковик, Нигма начинает формировать список документов, разделяя его на кластеры.
Каждое из этих множеств может быть отклонено, тогда поиск будет осуществляться с большей степенью релевантности.
К примеру, запросы, полученные из интернет-магазинов, образуют отдельный кластер – если вам не интересны подобные документы, просто исключите их из результатов.
Возможности сервиса: математика, химия, музыка
Nigma.ru имеет свои уникальные особенности, к примеру, использует умные поисковые подсказки.
Для того чтобы сориентироваться поисковик начинает выдавать их еще во время ввода самого запроса. Их условно можно поделить на три категории – короткие, точные запросы и энциклопедическая справка.
Начнем с короткого запроса, например, этого будет следующее сочетание:
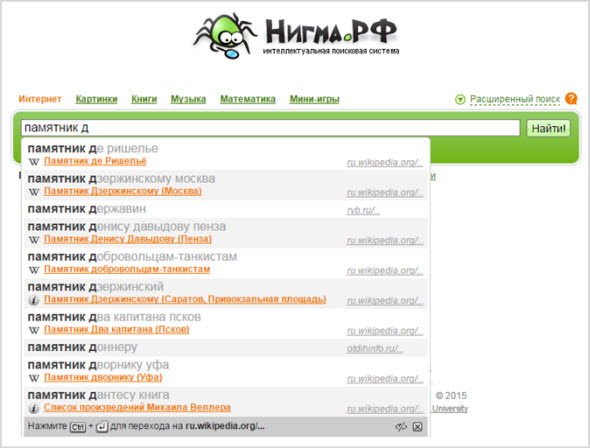
Вы можете просто выбрать нужный вариант, но перед этим можно никуда не заходя, получить историческую справку, всплывающую тут же отдельным блоком.
Более подробный запрос позволяет получить расширенную информацию об объекте поиска.
Нигма.рф также позволяет искать бесплатные торрент-трекеры без регистрации и рекламных блоков. Просто введите название фильма и слово «торрент» для этого:
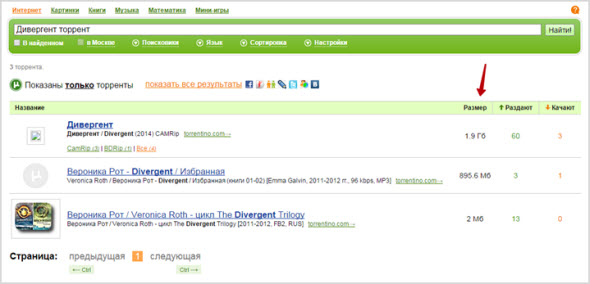
Можно вместо этого просто ввести фразу «скачать фильм» с указанием его названия и также получить отсылки на ресурсы torrent. В общем, интересная специализация, позволяющая сориентироваться в пространстве кинематографа.
У Нигмы есть еще множество различных так называемых фичей – то есть характерных особенностей.
Но более подробно сначала рассмотрим ее специализацию на решении различных задач по математике, химии, физике – этакий универсальный помощник для школьников.
Нигма-математика
Что собой представляет Нигма-математика? Это сервис, благодаря которому возможно в режиме реального времени решать различные математические задачки и делать вычисления – это и упрощение выражений, и даже решение систем уравнений.
Для этого нужно ввести их в качестве обычного запроса в поисковую строку.
Система Нигмы также распознает большое количество самых разных математических и физических констант, единиц измерения — получается результат операций с различными величинами.
Это как бы единый решебник, который также выполняет задачи по аналогии с калькуляторами поисковых систем и валютных конвертеров.
Вводить, к примеру, исходные данные для математических задач можно как при помощи знаков и цифр, так и в буквенном формате:
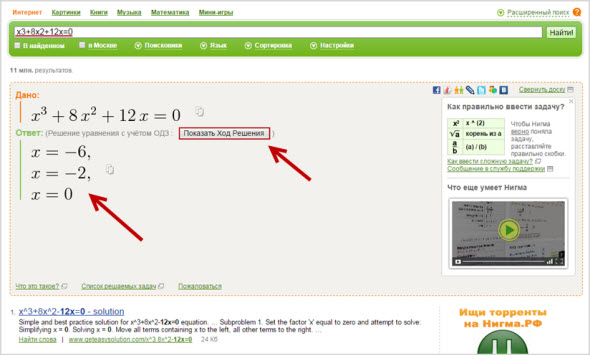
Вы можете использовать функцию «Показать ход решения», где по полочкам будут разложены, объяснены и расписаны промежуточные результаты уравнения. С левой стороны находиться блок с фильтрами.
Следующая возможность – уравнения с математическими выражениями, константы можно вводить как в сокращенном, так и полном виде:
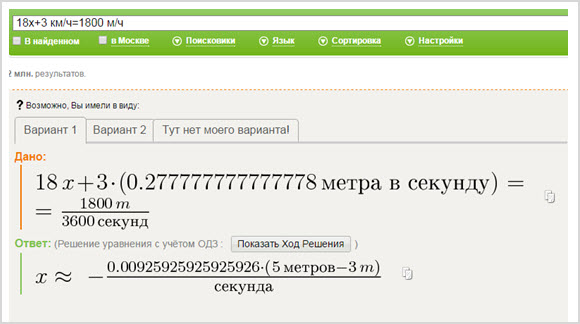
Кстати, конвертер валют – вещь сегодня актуальная, реализована она и в Нигме.
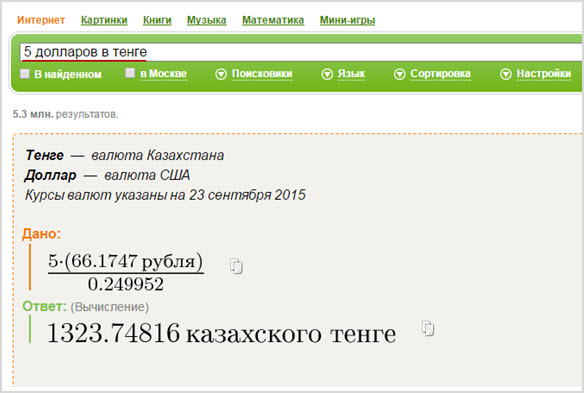
Запрос вводится следующим образом – сначала идет конвертируемая сумма, затем предлог «в» и затем название валюты, в которую нужно перевести:
Полный список решаемых Нигмой задач можно было найти внутри системы.
Нигма-химия
Задачки по химии даются не всем, но и проверять себя как-то надо, уж лучше пользоваться Нигмой, чем списывать ответы из ГДЗ. В любом случае Нигма-химия – это классный сервис для самообразования в данной области.
В соответствующем разделе можно найти ознакомительный ролик, чтобы понять как работать с системой. Она имеет дело как с неорганической, так и органической химией.
Чем полезна Нигма?
- Во-первых, вы можете выполнять поиск по отдельным химическим веществам, вводить можно либо краткими обозначениями (как в таблице Менделеева), либо просто написав название буквами:
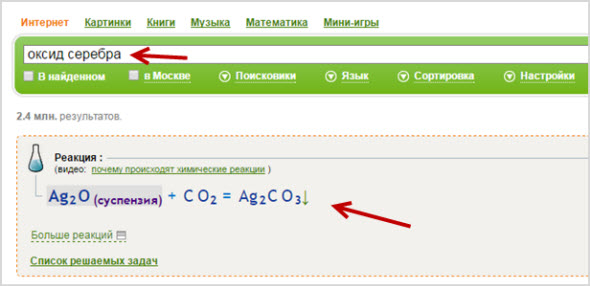
Вы увидите, какие с ними возможны химические реакции, нажмите «Больше реакций» и получите большое количество вариантов.
Естественно, чуть ниже вас ожидают ссылки на сайты с наибольшей релевантностью запросу.
- Во-вторых, сами искомые реакции можно найти, начиная вводить их в поисковике:
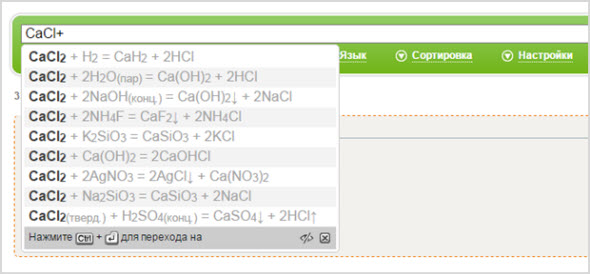
Можете быть уверены, что Нигма будет контролировать процесс – например, если по ошибке ввести формулу реакции, которой быть в принципе не может, система обязательно вас об этом известит.
Очень удобно – вы получаете соответствующие комментарии и советы по ходу.
В общем, просто палочка-выручалочка для юного химика, в любом случае вещь полезная и значительно упрощает жизнь сегодняшнему школьнику.
Были бы в наше время подобные системы! 🙂
Нигма-музыка
Поисковик имеет также мультимедийный раздел, посвященный поиску музыки и ее прослушиванию онлайн – Нигма-музыка.
Искать можно по композиции, исполнителю, альбому:
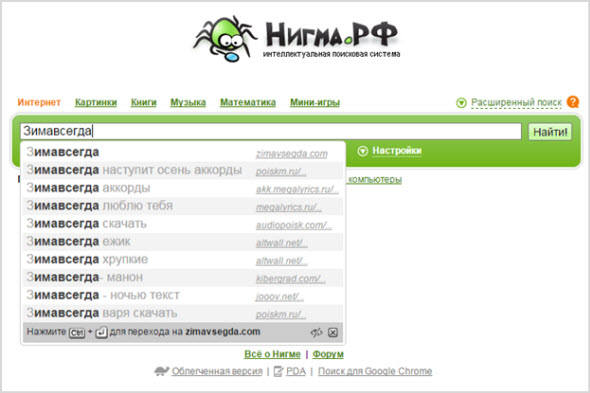
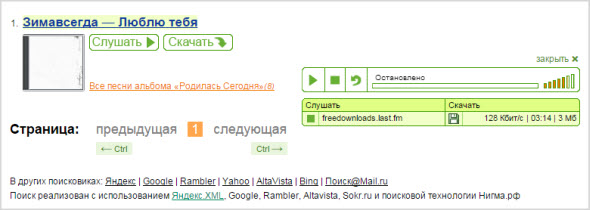
Прослушать можно прямо тут, а также скачать композицию, или перейти на приглянувшиеся сайты и сделать это уже там:
Еще одна любопытная функция – возможность загружать в Нигму музыку самостоятельно. Но доступно это только зарегистрированным пользователям.
Форма для заполнения прямо скажем непритязательная, так что много времени это не займет:
Вы моментально получите доступ к Личному кабинету, именно здесь для загрузки медиафайлов в звуковом формате нужно зайти в раздел «Моя музыка».
Там будет находиться плейлист загруженных файлов, форма собственно для загрузки, раздел «Помоги Нигма-музыке», где указан список последних 50 запросов, на который сервис не смог дать ответа.
Но вернемся к загрузке – нажмите по ссылке, которая представлена на странице раздела:
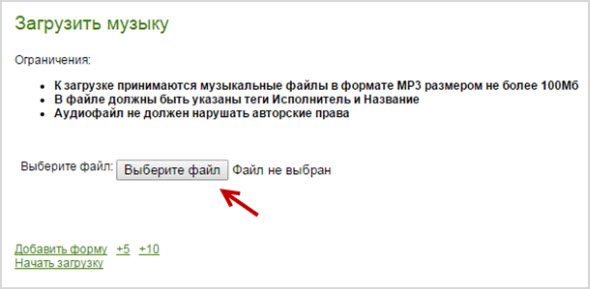
Нажмите «Выберите файл» и загрузите запись со своего компьютера и нажмите «Начать загрузку»:
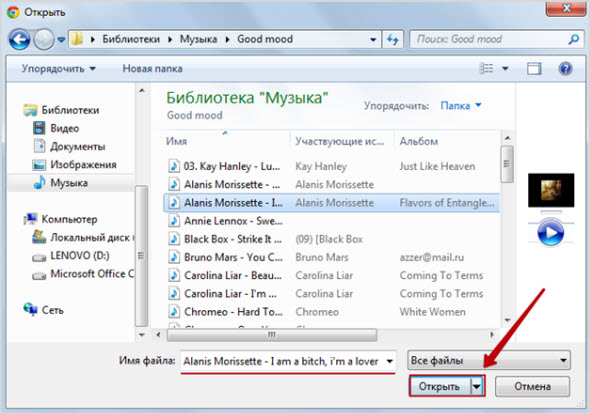
Результат появляется на этой же странице выбранного раздела:
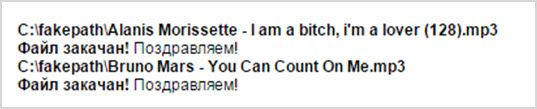
Зато список загрузок можно будет посмотреть на странице «Мои музыкальные файлы».
Дополнительные функции Нигмы
Это был далеко не полный список особенностей поисковой системы Nigma, некоторые разделы представляют особый интерес:
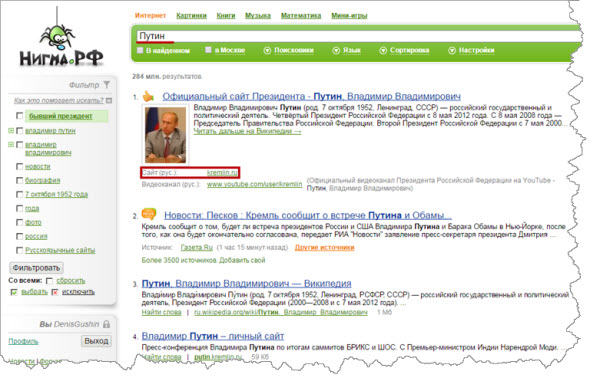
Официальные сайты. Нигма.рф повышает приоритетность в результатах первоисточников информации.
То есть, если вы хотите узнать что-то об определенном человеке, имеющем свой сайт или о компании, такая информация сразу появится в первых рядах:
Англоподсказка. Данный сервис занимается проверкой совместимости и частоты слов, употребляемых в английских выражениях. Вы вводите в поисковую строку какое-то выражение, если оно покажется системе неправильным, вам предложат корректные варианты.
Поиск по библиотекам. Для этого у сервиса имеется специальный раздел «Книги». Вы можете найти любую информацию по авторам, текстам произведений – всего по более чем 100 библиотекам, например, по фамилии автора:
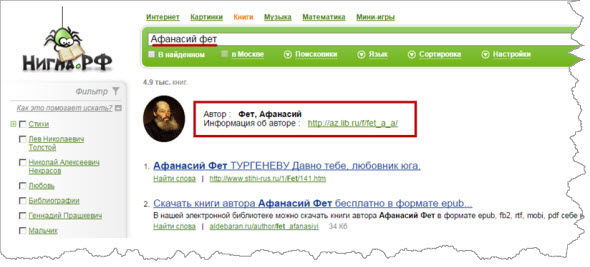
Для того чтобы отыскать конкретный текст автора, просто введите его название, можно и зарубежную.
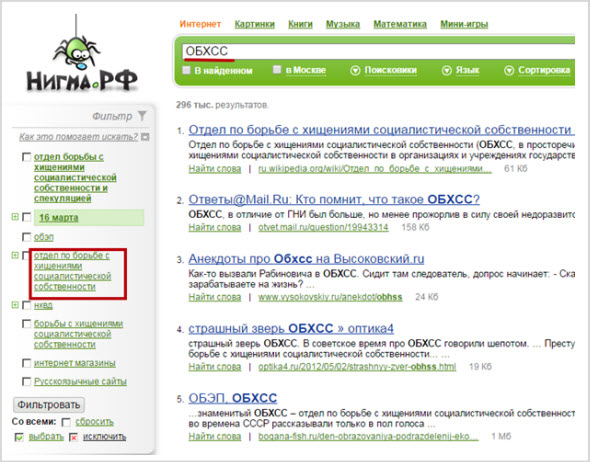
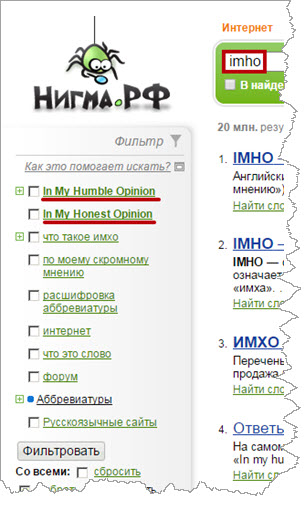
Расшифровка сокращений. Умная система распознает не только русскоязычные, но и англоязычные аббревиатуры. Просто введите в поисковике то, что вас интересует, кроме результатов слева, вы увидите варианты.
Начнем с русскоязычных сокращений:
И что-нибудь англоязычное для демонстрации возможностей сервиса:
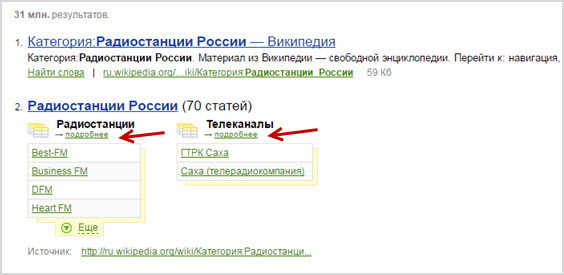
Табличный поиск от Нигмы. Автоматически можно получать данные об объектах в виде таблиц, поисковик был первым среди конкурентов, кто стал способен на такое.
Информация получается структурированной и легко читаемой.
Например, запросим «радиостанции России»:
Нажмите на «подробнее» и вы попадете на страницу, где результаты можно скачать в виде таблиц тут же:
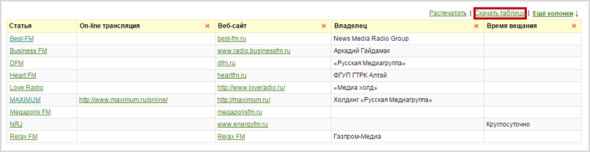
Выберите кодировку из представленных – windows-1251 или utf-8 (Mac/Linux/Unix) и скачайте документ на компьютер или просто сразу распечатайте на принтере.
Борьба со спамом. Данный сервис предоставляет пользователям возможность помогать в развитии поисковика. Просто пользуясь поисковой строкой и просматривая сайты, вы можете дать сигнал модераторам о том, что какой-то из них не очень благонадежен.
Нажмите на соответствующий значок «Корзина» и заявка будет рассмотрена.
К спаму могут относиться сайты со следующими характеристиками:
- Страница буквально напичкана ключевыми словами, в результате чего ее продвижение к верхним позициям в поисковике становится проще;
- Страница заполнена текстом без какой-либо логики – такие сайты генерируются автоматическим образом опять же для поднятия рейтинга;
- Могут быть и более «коварные» приемы для маскировки – как бы отсутствие текста, хотя на самом деле это белая заливка на белом же фоне или, например, текст присутствует, но он находится в блоках, которые не видны обычному пользователю;
- «Несанкционированные» переадресации на какие-то сторонние сайты;
- Просто несоответствие содержимого страницы заданному запросу;
Фильтр. Поисковые запросы в Нигме формируются в определенные блоки информации, помогают в этом многочисленные фильтры.
Вы можете уточнить запрос, используя их, темы можно включать и так же просто выключать.
Например, сделаем запрос «эйфелева башня», в колоночке слева и находятся все возможные фильтры к нему:
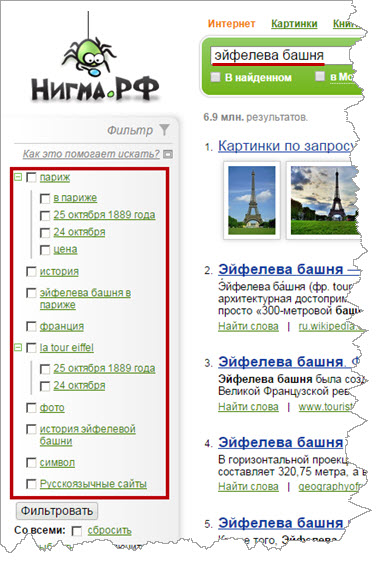
Что вы здесь видите? Дату открытия, историю башни, фотографии с ней, цены на ее посещение и т.д.
Теперь можно выбрать какой-то конкретный из фильтров, кликнув по нему. Таким образом вы сделаете свой запрос конкретнее и в выдаче появятся соответствующие результаты:
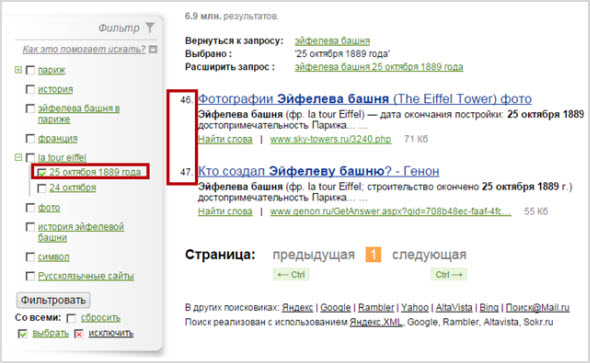
Управлять фильтрами несложно – для того, чтобы выделить любой из них, требуется отметить его напротив галочкой, еще раз кликнув, вы увидите уже не зеленую галочку, а красный крестик, это будет означать, что фильтр вы исключаете, далее нужно нажать на «Фильтровать»:
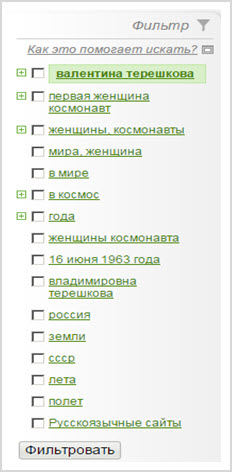
Кстати, при вводе запроса, первым в списке фильтров оказывается ответ на заданный вопрос, например, если вы введете «женщина космонавт», то получите следующее:
Вот, кажется, и все, что касается фильтров – их очень просто использовать, чтобы получить максимально точный ответ на запрос.
Нигма – действительно, интересный поисковик с собственной индивидуальностью, несмотря на использование индексов других поисковых машин (Вебальта, Mail.Ru, Апорт, Спутник, Metabot).
Сама система интересна, много различных полезных функций, главное, что все упорядочено и конкретно.
Есть, кстати, и расширенный поиск для большей точности запроса, тут же можно регулировать некоторые настройки, сортировку, сделать выбор языка для поиска, ограничить область поиска городом, например.
А еще здесь можно найти отсылку к мини-играм онлайн и картинкам.
Nigma (Нигма) — интеллектуальная поисковая система в интернете
Российская поисковая система «Нигма» являлась совместным продуктом бывшего вице-президента Mail.ru Виктора Лавренко и Владимира Чернышова, в то время являвшегося студентом кафедры вычислительной техники и кибернетики МГУ. Поисковик изначально отличал научно-прикладной характер, он являлся в некоторой степени исследовательской лабораторией для студентов МГУ. «Нигма» стала интеллектуальной поисковой системой, на базе которой были созданы и защищены многие дипломы и научные диссертации. Коммерческая составляющая проекта не была приоритетной целью, но сервис некоторое время имел активное рекламное продвижение. Название Nigma принадлежит одному из родов пауков и должно было иметь ассоциацию со Всемирной паутиной.
История создания и развития
Знакомство Виктора Лавренко и Владимира Чернышова состоялось в 2004 году на кафедре АСВК факультета вычислительной математики и кибернетики МГУ. Началом проекта послужили исследования в области искусственного интеллекта. Система Nigma была запущена 12 апреля 2005 года. Уже после запуска системы разработчиками был проведен ряд исследований поисковых запросов от пользователей. На основании этого были изменены привычные алгоритмы, позволявшие выдавать необходимую информацию уже на странице поиска. В 2007 году Владимир Чернышов при сотрудничестве Стэнфордского университета разработал алгоритм, позволяющий обрабатывать информацию из страниц сайтов и представлять ее пользователям в виде таблицы, включающей основные интересующие значения.

Таким образом, «Нигма» в первую очередь занялась разработкой определенных ниш в сфере поиска в интернете, не конкурируя напрямую с главными поисковиками. В 2008 году в поисковик сделал существенный денежный вклад бизнесмен Юрий Мильнер, в то время владевший долями Mail.ru, а также социальных сетей «ВКонтакте» и «Одноклассники». Переговоры фонда Digital Sky Technologies, принадлежащего Юрию Мильнеру, продолжались около года, после чего доля компании перешла бизнесмену. Начиная с 2009 года «Нигма» пыталась выйти на рынок Вьетнама, которому требовалось создание аналогичной поисковой системы, учитывающей особенности вьетнамского языка. Вьетнамский рынок был выбран и по той причине, что развитие интернета в этой азиатской стране имело на тот момент достаточно высокие показатели (7 %, или 28 миллионов новых пользователей за год). Результатом работы стал поисковик CocCoc, развитием которого продолжает заниматься Лавренко.
Принцип работы
Поиск в системе «Нигма» осуществлялся как по собственным алгоритмам, так и по индексам поиска крупных поисковых систем, таких как Google, «Яндекс» или Bing. Основным отличием от других поисковиков являлось разделение получаемой информации по определенным тематическим категориям – кластерам. Крупные поисковики делают ставку на многозадачность, что не всегда позволяет пользователю найти необходимую информацию. В настройках «Нигмы» можно было включать фильтры, сужающие область поиска, а значит, повышающие вероятность выполнения требуемого запроса.

Настройки позволяли как задавать необходимые параметры, так и удалять их из общей подборки. Таким образом отсеивается большое количество ненужных ресурсов, выдаваемых при поиске. Кроме того, система использовала и привычные интеллектуальные подсказки, появляющиеся при постепенном вводе буквенных и цифровых значений в строку поиска. Можно было задавать для поисковика параметр нахождения информации по точной фразе либо на конкретном ресурсе.
Популярность и распространение
По словам разработчиков, основную аудиторию поисковика должны были составлять студенты, а возможность кластеризации могла обеспечить приток большого количества новых пользователей. Но популярность системы продолжала оставаться достаточно низкой на фоне таких крупных сервисов, как Google и «Яндекс». В 2007 году, по данным LiveInternet, доля переходов с «Нигмы» составляла 0,4 % от общего числа пользователей. Однако этот показатель был выше, чем у одного из старейших российских поисковых сервисов – «Апорт» (0,3 %). Руководство Nigma проводило достаточно активную кампанию по привлечению новых пользователей, которые могли бы стать одновременно и испытателями, что было нужно для развития. Какое-то время сервис рекламировался на «Яндекс.Директ», что принесло более 110 тысяч переходов. Также проводились рекламные кампании в радиоэфире, что способствовало небольшому росту популярности. Однако в 2007 году реклама в «Яндекс.Директ» прекратилась из-за нежелания более крупного сервиса продолжать сотрудничество. Существовала также версия сервиса для устройств, работающих на операционной системе Android.
Сервисы поисковой системы
Помимо непосредственного поиска в сети, «Нигма» обладала другими интересными возможностями, не характерными для многих поисковых сервисов. В частности, это был поиск по музыке или торрентам, а также вычисление математических и химических формул.
Выделение официальных сайтов. Многие поисковые системы никак не выделяют ссылки на официальные ресурсы компаний, заставляя пользователей тратить дополнительное время на их обнаружение. «Нигма» решила этот вопрос выделением таких сайтов особым значком – «палец вверх». Как правило, данная ссылка располагалась вверху поиска и была достаточно заметной и понятной пользователям. Также при желании можно было посмотреть полный список официальных сайтов в случае совпадения названий организаций или фамилий.

Решение математических и химических задач, конвертер. Как уже было сказано, «Нигма» пользовалась относительно высокой популярностью у школьников и студентов. Это обеспечивали возможности по вычислению различных уравнений, которые система легко распознавала в любом варианте написания. Математическая система впервые была запущена в октябре 2008 года.

Это пример стандартного написания задачи в поисковой строке. Также «Нигма» может подробно показать ход решения, если это необходимо. Ход решения выдавался к следующим типам задач:
-
линейным уравнениям;
-
уравнениям вида f(x) = c, где f – логарифм, экспонента, тригонометрическая функция;
-
приведению к общему знаменателю;
-
биквадратным и бикубическим уравнениям.
Помимо линейных уравнений, поисковик был способен решать и задачи с единицами измерения. Необходимо было ввести математическое выражение, содержащее соответствующие условия в сокращенном или полном виде. Еще одной особенностью была возможность написания задачи в виде текста с последующим автоматическим переводом в формат уравнения. Пример такого написания:

Помимо математического сервиса, «Нигма» предоставляла возможность решения химических формул, а также имела встроенный конвертер систем величин и валют, в том числе и с использованием жаргонных выражений. Курс валют выдавался в соответствии с показателями Центрального банка России.

Запуск химической системы состоялся в декабре 2008 года. Первоначально «Нигма» обрабатывала запросы по неорганической химии, по конечным и исходным веществам реакции. Поддержка органической химии появилась позднее. К 2011 году система могла проводить решение более чем 12 000 реакций. Вещества можно было вводить как в виде формул, так и по их названию.

Еще одной отличительной особенностью сервиса «Нигма-Химия» была возможность поиска и расшифровки химической формулы по ее названию. Достаточно было ввести в поисковую строку наименование и тут же получить ответ. Пример:


Конструктор поиска. Любой пользователь мог поместить поисковую форму от «Нигмы» на личный сайт, оформив по своему усмотрению. Это производилось за несколько шагов:
-
выбор варианта оформления строки и кнопки поиска;
-
установка типов и мест поиска;
-
добавление ссылки на свой сайт и указание кодировки.
После получения кода его необходимо поместить на сайт, завершив таким образом добавление поисковой формы. Главным неудобством было отсутствие вычислительных возможностей «Нигмы» при использовании данной формы.
Поиск по книгам и картинкам. Возможность искать информацию по изображениям в настоящее время появилась во всех крупных поисковых системах. «Нигма» осуществляла подборку в соответствии со своим принципом группировки информации по кластерам. Изображения достаточно быстро фильтровались по форматам, размерам и категориям. Поиск книг при вводе их названия в поисковой строке выдавал в первую очередь ссылки на бесплатное скачивание, а не на магазины. Система кластеров работала и здесь, позволяя качественно отфильтровать поступающую информацию.

Поиск музыки и торрент-файлов. Возможность поиска музыки в системе «Нигма» за счет использования кластеров становилась очень удобной для пользователей. Поисковик позволял отфильтровать жанры, альбомы и сами композиции, превращая панель категорий в полноценный рубрикатор. Также система в первую очередь предлагала в выдаче ссылки на прослушивание и скачивание файлов, а предпрослушивание можно было осуществлять через встроенный в систему плеер, в котором можно было прослушать песню перед скачиванием с указанием ее битрейта.

Для некоторых композиций была доступна возможность просмотра ее текста. Зарегистрированные пользователи имели возможность лично загружать музыкальные файлы в систему. После этого они становились доступны всем пользователям. При поиске торрентов «Нигма» выдавала ссылки на них с указанием числа скачивающих и раздающих, а также размер скачиваемого файла.

Интеллектуальный поиск. Подсказки при введении запроса в поисковую строку в настоящее время стали привычными для всех поисковых систем. «Нигма» в этом вопросе сделала дополнительный шаг, предоставив возможность предпросмотра потенциальных запросов уже в выпадающем списке. Предлагаемые варианты содержат ссылки с указанием краткой, а иногда и полной информации. Причем речь идет только о возможных вариантах вводимого запроса. Кроме того, это решение распространяется и на интернет-магазины, позволяя увидеть предложения товаров с ценами на конкретном ресурсе. Также сервис мог расшифровывать русскоязычные и англоязычные аббревиатуры.

Новости. Кроме того, «Нигма» выдавала пользователям на странице результатов поиска три самые свежие на текущий момент новости. База данных обновлялась каждые пять минут, а источниками новостных данных являлись более 3500 RSS-лент различных СМИ и блогов. Зарегистрированные пользователи также могли добавлять информационные ресурсы в индекс системы.
Современное состояние
19 сентября 2017 года сайт nigma.ru, равно как и нигма.рф, перестал отвечать на запросы пользователей. Спустя некоторое время один из основателей ресурса заявил, что о закрытии речи не идет, так как «Нигма» продолжает приносить прибыль. Тем не менее с 2018 года поисковик больше не работает. В настоящее время существует бета-версия поисковой системы по адресу nigma.eu, которая лишена всех прежних возможностей и предоставляет упрощенный вариант поиска в сети.

Несмотря на скромные начальные ресурсы, система «Нигма» имела определенную популярность у некоторых пользователей за счет возможностей сервиса, которые на момент его наивысшей популярности давали преимущество даже перед крупными поисковиками. Однако ряд факторов помешал сайту представить существенную конкуренцию на рынке поисковых систем.
Интеллектуальные поисковые системы Excalibur | Сети/Network world
В условиях постоянного роста объемов информации, обрабатываемой как внутри отдельных предприятий, так и в рамках корпоративных и глобальных сетей, именно от эффективности и производительности поисковых систем зависит, превратятся ли в знания многочисленные разрозненные данные, поступающие по различным каналам связи и накапливаемые в разнообразных государственных, ведомственных, частных и прочих электронных архивах.
Объемы обрабатываемой электронной информации нарастают сегодня стремительными темпами — этому способствует активное использование мощных СУБД, быстрое развитие мультимедиа, широкое распространение корпоративных и глобальных сетей. В создавшихся условиях резко возросла потребность в системах поиска и анализа данных. Традиционные системы поиска, которые развивались в тесной взаимосвязи с СУБД, в основном ориентированы на работу со структурированными текстовыми данными и мало приспособлены для обработки мультимедийной информации и данных, поступающих в оперативном режиме. Как показывает статистика, доля структурированных данных в современных архивах составляет не более 20%, остальные же 80% приходятся на долю различных документов, сканированных текстов и другой разрозненной информации. Кроме того, в связи с быстрым развитием мультимедиа изменился характер обрабатываемых документов; наряду с текстовой информацией в них включается графика, видео, звук.
Таким образом, все острее встает проблема организации поиска и анализа для цифровых данных произвольного типа, обработка которых традиционными средствами SQL СУБД оказывается мало эффективной. Обычно в этих системах полнотекстовая индексация строится на базе инвертированных списков, в которых словам или нормализованным словоформам ставятся в соответствие адреса документов. Объем индекса при таком подходе зависит от степени нормализации исходного текста и при работе с неструктурированными данными может достигать 300% от общего объема базы. Этот метод индексации оказывается также мало пригодным при работе с графическими и другими цифровыми данными в связи с их большой насыщенностью и многообразием. Для кардинального решения проблемы индексации и поиска информации необходимы принципиально новые методы.
Один из таких альтернативных подходов — технология, разработанная компанией Excalibur Technologies и объединившая в себе метод адаптивного распознавания образов (APRP — Adaptive Pattern Recognition Processing) и семантические сети. Она позволят работать с цифровой информацией любого типа — текстом, графикой, видео и др. Метод APRP опирается на теорию нейронных сетей и позволяет осуществлять бинарную индексацию, при которой размер индекса даже при обработке неструктурированной информации не превышает 30% от размера исходных данных. Программные средства Excalibur позволяют вести ранжированный индексный поиск и поиск по шаблонам. В качестве шаблонов могут выступать фотографии, наброски, фрагменты текста и др. Применение технологии семантических сетей обеспечивает возможность использования естественного языка запросов и позволяет вести интеллектуальный поиск на основе баз знаний.
Сегодня основными продуктами компании Excalibur являются RetrievalWare, EFS и Visual RetrievalWare. Первые два ориентированы на работу с текстом, а Visual RetrievalWare предназначен для обработки изображений. На рис.1 приведена схема взаимодействия основных компонентов Excalibur, указаны применяемые в них методы поиска, а также поддерживаемые аппаратные платформы и операционные среды.

Рисунок 1.
Архитектура RetrievalWare.
Различные подходы к построению поисковых систем
Основные критерии оценки эффективности поисковых систем — скорость, точность и полнота ответов. Точность определяется тем, какая часть информации, выданной в ответ на запрос, является релевантной, т. е. относящейся к этому запросу. Полнота характеризуется соотношением между всей релевантной информацией, имеющейся в базе, и той ее частью, которая включена в ответ. Кроме этого при оценке поисковых систем учитывается, с какими типами данных может работать та или иная система, в какой форме представляются результаты поиска и какой уровень подготовки пользователей необходим для работы в этой системе.
Традиционные подходы к организации поиска информации можно разделить на три группы: методы индексного (или двоичного) поиска, статистические методы и методы, основанные на базах знаний.
Индексный, или двоичный, поиск применяется главным образом со структурированными базами данных. В таких методах слова интерпретируются как последовательности закодированных символов. Используя формальный синтаксис, или язык запросов, система двоичного поиска выбирает точное соответствие для отдельного слова, цепочки слов или слов, связанных логическими операторами. Применение искусственного языка запросов приводит к необходимости обучения пользователей двоичной логике, которая не является интуитивно понятной и трудна в использовании. Системы двоичного поиска имеют ограничения по точности, влияющие на возможность нахождения всей относящейся к запросу информации. В методах двоичного поиска не учитываются различные формы и значения слов; пользователю непросто угадать точные слова и фразы, которые были использованы авторами в документах. Системы двоичного поиска не могут также ранжировать документы по степени соответствия запросу, поэтому пользователь вынужден читать каждый документ, чтобы определить, насколько он соответствует запросу.
Статистические методы основываются на расчете различных частотных характеристик: частоты вхождения слова в документ, взвешенной частоты вхождения и частоты совместного вхождения нескольких слов. При этом предполагается, что чем чаще встречается то или иное слово запроса в документе, тем в большей степени данный документ соответствует введенному запросу. Основной единицей информации, которой оперируют статистические методы, является отдельное слово, однако связи между словами рассматриваются исключительно с математической, а не с лингвистической точки зрения. В отличие от методов двоичного поиска статистические методы не требуют применения жестко формального языка запросов. Они позволяют проводить ранжирование документов по степени соответствию запросу, что существенно повышает эффективность работы с поисковыми системами. Однако такие методы не всегда позволяют получить желаемые точность и полноту ответов, поскольку важность того или иного термина не напрямую связана с частотой его использования в документе.
Системы, основанные на базе знаний, занимаются поиском информации на основе некоторых внешних знаний. Они используют концептуальные отношения, которые не применяются при статистическом поиске.
Системы, основанные на базах знаний, гораздо удобнее тех, которые базируются на двоичном поиске. Однако сегодня лишь подход, основанный на построении семантических сетей, свободен от ограничений, присущих двоичному поиску; он обладает достаточной гибкостью, доступен для расширения и не слишком громоздок при эксплуатации.
Особенности технологии поиска Excalibur
Концептуальный поиск на основе семантических сетей привносит элементы искусственного интеллекта в информационно-поисковые системы. Именно этот подход использован в системе Excalibur. Однако, как можно заметить, методы поиска, основанные на базах знаний, предназначены для работы в области текстовых данных. Преодолеть это ограничение в поисковых системах Excalibur удалось за счет совместного использования технологии семантических сетей и методики адаптивного распознавания образов APRP.
Метод адаптивного распознавания образов базируется на принципе биологических нейронных сетей — система функционирует как самоорганизующийся организм; анализируя данные, она выделяет и запоминает присущие этим данным двоичные конфигурации-шаблоны. APRP автоматически индексирует выделенные двоичные шаблоны, создавая тем самым структурированную память, оптимизированную в соответствии с внутренним содержанием данных. Наряду с идеологией нейронных сетей в APRP используется также методология нечеткого поиска, которая обеспечивает устойчивость поисковых процедур к ошибкам, содержащимся во вводимых данных или терминах запросов. Подход, основанный на APRP, позволяет достичь высокой скорости поиска информации, добиться расширяемости системы и эффективного использования вычислительных ресурсов.
Ряд других особенностей технологии Excalibur связан с использованием семантических сетей, позволивших кардинально изменить работу с текстовыми базами данных и предоставивших возможность осуществления автоматического поиска информации с применением запросов на естественном языке. Семантические сети объединяют синтаксис, морфологию и семантику языка, они используют полные словари, тезаурусы и другие семантические ресурсы, предоставляя в распоряжение пользователей встроенную базу знаний для ведения интеллектуального поиска информации. Например, английский вариант сети охватывает около 0,4 млн смысловых значений слов и свыше 1,6 млн связей между словами.
В процессе поиска информации пользователь может сформулировать свой запрос непосредственно на родном ему языке, например английском. Этот запрос автоматически дополняется набором связанных между собой терминов и понятий. Алгоритмы морфологического разбора, применяемые в Excalibur, позволяют различать разнообразные формы слов, заданных в запросе, даже с учетом возможных орфографических ошибок. Для обеспечения более точного поиска проводится анализ, направленный на выявление идиоматических выражений, встретившихся в запросе. Словосочетания типа «недвижимое имущество» воспринимаются как единые понятия, а не наборы отдельных слов. Кроме того, распознаются разные значения слов. Пользователь имеет возможность указать, в каком из множества значений употреблено слово в конкретном запросе. Базовая семантическая сеть Excalibur поддерживает многоуровневые структуры словарей, которые объединяют специализированные термины по юридическим, медицинским, финансовым, техническим и другим дисциплинам. Конечный пользователь может также добавить свои определения и понятия, не нарушая целостности основной базы знаний.
Важным преимуществом Excalibur является возможность представления результатов поиска в виде списка документов, отсортированных по степени соответствия запросу. Это значительно повышает эффективность работы с данными и позволяет сразу получить наиболее важную информацию, не просматривая подряд все выделенные документы. Однако точность ранжированного поиска существенно зависит от критериев, которые используются для оценки релевантности документов. Обычно для оценки степени соответствия применяется непосредственный статистический анализ. Иногда база данных разбивается на отдельные сегменты, или порции, и оценка релевантности проводится отдельно по каждому сегменту. Это повышает скорость поиска, но может привести к снижению точности, так как документ, наиболее важный в некотором сегменте, может не оказаться таковым в рамках всей базы. При оценке степени соответствия документа кроме статистических методов поиска используется ряд дополнительных критериев, основанных на значении слов и их синтаксической роли. В общей сложности можно выделить семь основных критериев, которые учитываются при ранжировании документов: частота вхождения понятия в документ; близость понятий документа к запросу; частота вхождения понятия в остальную часть базы данных; близость понятия к другим понятиям и терминам документа; важность понятия, основанная на его синтаксической роли; важность понятия, основанная на его спецификации; позиция понятия в списке наиболее важных понятий документа.
Программные продукты Excalibur, соединяющие в себе APRP-технологию, семантические сети и естественный язык запросов, принадлежат к поисковым системам нового поколения. При работе с различными источниками данных они позволяют не просто извлекать разрозненные сведения, а получать актуальную, доступную, точную, полную и своевременную информацию.
Средства анализа и поиска текстовой информации RetrievalWare
Excalibur RetrievalWare занимает центральное место в семействе программных продуктов Excalibur. Интеграция методики адаптивного распознавания образов и технологии семантических сетей позволяет системе RetrievalWare обеспечить высокую производительность на всех этапах обработки текстовой информации, начиная от сбора и индексации данных и кончая их поиском и распространением.
RetrievalWare построена на основе гибкой — модульной — архитектуры, которая обеспечивает масштабируемость в распределенной среде клиент-сервер, поддерживает работу с обширными базами данных и большим количеством пользователей. Excalibur RetrievalWare представляет собой инструментальную систему, включающую в себя широкий набор текстовых серверов и развитые средства разработки приложений (SDK). В состав SDK входят высокоуровневые интерфейсы API, предназначенные для создания пользовательских интерфейсов GUI на основе таких средств, как Visual Basic; средства вызова удаленных процедур, обеспечивающие проектирование систем, которые поддерживают работу с большим числом удаленных пользователей; прикладные интерфейсы низкого уровня, позволяющие адаптировать поисковые возможности RetrievalWare к требованиям конкретных потребителей.
Текстовые серверы Excalibur RetrievalWare обеспечивают высокопроизводительный полнотекстовый поиск для больших информационных систем. В них входит расширяемый набор модулей индексации, поиска и отображения данных, которые допускают гибкую конфигурацию, могут работать на процессорах различных типов и поддерживают протоколы TCP/IP. Excalibur RetrievalWare включает в себя несколько серверов, предназначенных для текстового поиска.
Применение технологий Excalibur позволяет повысить эффективность работы как с неструктурированной цифровой информацией, так и с традиционными базами данных. Компания Excalibur сотрудничает с разработчиками СУБД Oracle, Informix, Sybase, CA и др. Наиболее тесные связи установлены с компанией Informix, для которой Excalibur создает встроенные модули Data Blade, предназначенные для работы как с текстами, так и с изображениями. Сегодня пользователь или системный интегратор, использующий имидж-сервер в качестве Data Blade, может создавать приложения на базе обоих продуктов. В принципе, как утверждают разработчики Excalibur, они могут проиндексировать любую базу данных и обеспечить тем самым неструктурированный доступ к структурированным данным. Например, Pacific Bell At Hand заключила соглашение с Excalibur и объединила RetrievalWare с реляционными базами данных Oracle и Java-интерфейсом, что позволило компании не только проиндексировать информацию, но и улучшить качество обслуживания пользователей.
Система ведения электронных архивов Electronic Filing Software
Сегодня, несмотря на широкое распространение автоматизированных систем документооборота и делопроизводства, огромное количество оперативной и справочной информации по-прежнему остается на бумажных носителях, что стимулирует развитие новых информационных технологий построения электронных архивов, обеспечивающих хранение больших объемов документов в электронном виде и доступ к ним.
Система Electronic Filing Software (EFS) предназначена для автоматизации различных видов деятельности, связанных с ведением электронных архивов; она предоставляет средства для сбора, хранения документов и организации поиска информации. EFS может работать на различных платформах с разнообразными типами документов, поступающих из многочисленных источников, в частности распределенных по локальным и глобальным сетям.
В этой системе бумажные документы вводятся с помощью сканера, а электронные могут считываться с оптических дисков, магнитной ленты или быть получены с помощью модема. EFS поддерживает большинство известных форматов текстовых и графических файлов, а также имеет встроенные средства оптического распознавания текста (OCR). Необходимо отметить, что, благодаря использованию технологии ARPR, EFS (в отличие от других подобных систем, где ошибки сканирования являются основным препятствием к успешной работе с архивами) менее чувствительна к погрешностям распознавания текста, поэтому позволяет осуществлять поиск без дополнительной корректировки и уточнения введенного текста. При работе с документами это позволяет экономить от 1 до 10 дол. на страницу текста, что является важным преимуществом, особенно ощутимым для организаций, осуществляющих электронное дублирование большого количества бумажных документов.
После того как документ введен в EFS, проводится автоматическое индексирование полного содержимого этого документа по технологии ARPR. Кроме того, по выбору пользователя документ может быть каталогизирован в базе данных с помощью набора определяемых пользователем полей или сохранен в электронном архиве Excalibur. Технология адаптивного распознавания образов, применяемая в EFS, дает возможность индексировать все содержимое текста, однако индекс не превышает одной трети от размера исходного документа, что позволяет достичь максимальной производительности при минимуме затрат на хранение информации.
Обеспечение быстрого и эффективного поиска информации — основная цель всех систем ведения электронных архивов. EFS позволяет осуществлять поиск несколькими независимыми способами:
- контекстный поиск по полному содержимому документов;
- контекстный поиск по названиям документов и меткам файлов;
- контекстный поиск с введенными пользователем синонимами по всему тексту документа;
- непосредственный доступ к файлам;
- поиск по SQL-запросам;
- ключевой поиск по тексту, именам и меткам;
- двоичный поиск по всему тексту.
Наличие графического пользовательского интерфейса, который создает удобную среду, привычную для всех кто знаком с офисной работой, дает возможность свести к минимуму затраты на переподготовку специалистов и обучение их приемам работы с электронными архивами. Режим нечеткого поиска уменьшает последствия погрешностей распознавания текста, ошибок ввода данных, а также сводит к минимуму влияние орфографических ошибок, допущенных в самом запросе.
EFS поддерживает технологию клиент-север для всех популярных аппаратных платформ, операционных систем, сетей и баз данных. Она может быть установлена на рабочих станциях и серверах UNIX производства компаний Sun, IBM, Digital и Hewlett-Packard. Обеспечивается также поддержка клиентов Windows и Macintosh для всех аппаратных платформ. EFS поддерживает связь с внешними базами данных, в том числе Oracle, Informix, Digital Rdb, Sybase, Ingres (Ultrix/SQL). В состав EFS входит WebFile, обеспечивающий доступ для чтения архивов EFS через Web-браузер. Для того чтобы начать поиск по архивам EFS, пользователю достаточно иметь поддерживаемый EFS Web-браузер и соединение с локальной сетью или с Internet.
Средства анализа и поиска мультимедийной информации
Подсистема Visual RetrievalWare предоставляет инструментальные средства для создания программного обеспечения, предназначенного для обработки произвольной мультимедийной цифровой информации. В состав Visual RetrievalWare SDK входит несколько графических интерфейсов разработки приложений различных уровней. Для UNIX-версий Visual RetrievalWare SDK поставляются статические библиотеки, а версия для Windows 95 и Windows NT, кроме того, включает в себя библиотеки импорта и динамически загружаемые библиотеки DLL. На основе Visual RetrievalWare SDK могут быть разработаны как самостоятельные приложения, так и отдельные модули, входящие в состав более крупных систем, для которых обработка изображений — лишь одна из многих решаемых задач. Visual RetrievalWare поддерживает режим многопроцессорной обработки.
Visual RetrievalWare SDK предоставляет средства для выполнения различных традиционных операций с изображениями, таких как загрузка, сохранение, копирование, отсечение, поворот, масштабирование и др., а также специальные компоненты для организации индексации и поиска цифровой информации. Все это позволяет проводить сравнение цифровых данных и осуществлять ранжированный поиск изображений по шаблону-образцу. Допускается обработка произвольных изображений — двоичных, полутоновых и цветных. Visual RetrievalWare поддерживает работу с различными графическими форматами — TIFF, GIF, JPEG, BMP и др. Изображения могут быть введены с помощью сканеров, получены по видеоканалам (VCR и др.), загружены из сети или созданы с помощью каких-либо графических редакторов.
Основу технологии Visual RetrievalWare, как и всего семейства программных продуктов Excalibur, составляет метод адаптивного распознавания образов. Каждому изображению, обрабатываемому в Visual RetrievalWare, ставится в соответствие некоторый двоичный вектор признаков, называемый дескриптором. Дескриптор формируется в результате анализа и сжатия изображения. Анализ осуществляется для выявления отличительных признаков, а сжатие позволяет уменьшить размер дескриптора по сравнению с размером исходных данных. Дескрипторы хранятся в базе, связанной с базой основных изображений. Именно дескрипторы используются для индексации, сравнения и поиска цифровой информации; на их основе автоматически устанавливаются гиперссылки в базе изображений. В процессе поиска информации по технологии Visual RetrievalWare дескриптор шаблона сравнивается с дескрипторами данных, хранящихся в базе. В итоге выдается список изображений, ранжированный по степени сходства с образцом. При этом пользователь может задавать различные весовые коэффициенты для конкретных параметров (композиции, цвета, контрастности).
В Visual RetrievalWare SDK имеются встроенные средства для выделения признаков и составления дескрипторов изображений. Размер дескриптора обычно бывает фиксированным, он не превышает 1% от объема исходного изображения. Использование дескрипторов позволяет сократить индекс и повысить скорость поиска цифровой информации. Однако слишком сильное сжатие ухудшает точность сравнения, поэтому в Visual RetrievalWare SDK предусмотрена возможность варьирования размера дескриптора для достижения наилучшего баланса между скоростью и точностью сравнения.
Алгоритмы, используемые в Visual RetrievalWare, имеют высокую производительность и позволяют обрабатывать большие объемы цифровой информации — это главное их преимущество перед традиционными методами сравнения изображений, основанными на корреляционном анализе. Проведение корреляционного анализа требует выполнения сложных математических вычислений, которые занимают значительно больше расчетного времени, чем побитовые операции, выполняемые при сравнении дескрипторов. Однако корреляционные методы являются более точными, поэтому для достижения наилучших результатов возможно совместное использование двух подходов. В этом случае поиск осуществляется в два этапа: сначала путем сравнения дескрипторов выделяется ограниченное подмножество изображений, схожих с заданным шаблоном, а затем внутри этого подмножества применяется корреляционный анализ для выявления более точного соответствия.
Программные средства Visual RetrievalWare будут интересны всем организациям и специалистам, много работающим с изображениями, — военным, криминалистам, службам безопасности, разведке, таможне, а также представителям более мирных профессий, в том числе искусствоведам, дизайнерам, научным работникам и картографам. Недавно Visual RetrievalWare был интегрирован в поисковую систему Internet Yahoo! для реализации интеллектуального поиска изображений. Теперь обратившись по адресу http://www.yahoo.com, можно не только найти текстовый фрагмент или ссылку на документ, но и использовать изображение в качестве поискового образа.
* * *
Программные продукты Excalibur представляют собой средства интеллектуального поиска информации и позволяют повысить эффективность работы специалистов из разных прикладных областей. Поисковые системы Excalibur обеспечивают единую среду для работы с самыми разнообразными документами — электронными архивами, неструктурированными данными, информацией, оперативно поступающей по различным каналам связи, структурированными данным, хранящимися в различных базах данных и др. Повышая скорость и точность поиска нужной информации, технологии Excalibur позволяют высвободить дополнительное время для анализа и осмысления, что влияет на скорость и качество принятия решений. Новые решения предоставляют эффективные средства работы с огромными информационными ресурсами, такими как корпоративные сети и Internet, позволяя более полно использовать огромную мощь и потенциал современных информационных систем.
Возможности программных продуктов Excalibur по достоинству оценены многими компаниями. Например Всемирный банк включил Excalibur RetrievalWare в свою корпоративную сеть в качестве стандартного средства доступа к данным, различным по типу и местоположению. Известные компании, издательства и информационные агенства (например, Chicago Tribune, Internet Financial Network, Global Financial Information, Control Data Corp., Sequent, Sierra On-Line, The Los Angeles Times и командование ВМФ США) также активно используют решения от Excalibur. Все большее распространение получают программные продукты Excalibur и в России, их применяют Конституционный суд, ГУИР ФАПСИ, агенство занятости АНКОР, страховые компании и ряд других.
Получить более подробную информацию о поисковых средствах компании Excalibur Technologies, а также просмотреть примеры выполнения поиска можно на Web-сервере компании по адресу http://www.excalib.com.
Елена Карташева — Институт математического моделирования РАН, Москва; тел. (095) 972-3855.
Поделитесь материалом с коллегами и друзьями
Нигма РФ — интеллектуальная поисковая система с уникальным набором фишек (Математика, Химия, Торренты)
Предметом сегодняшней статьи будет Нигма – это интеллектуальная поисковая система, выделяющаяся среди всех конкурентов необычной системой поиска, позволяющей быстро находить нужное и отсеивать шлак.
Содержание:
При обсуждении поисковиков в сообществе вебмастеров и оптимизаторов принято упоминать Яндекс и Гугл, все остальное остается за скобками, иногда вспоминают про mail.ru, но о nigma.ru речи не идет совсем.
Спрашивается – почему? Все дело в трафике. Владельцев сайтов интересуют переходы посетителей, а доля Нигмы в Рунете ничтожно мала. Непопулярные поисковики не представляют интереса – ими пользуется слишком мало людей, чтобы тратить внимание и время.
Между тем, для простого пользователя сети, поисковая система Нигма куда как более интересна, нежели ее именитые конкуренты.
Интеллектуальная система поиска
Уникальность Нигма.рф (или Нигма Ру) заключается не в секретных алгоритмах ранжирования веб страниц, а в умении собрать, отсортировать и обработать информацию таким образом, чтобы на экран вышли только нужные ответы и пользователю не пришлось перебирать сайт за сайтом, натыкаясь на разные ГС и не тематические ресурсы.
Она очень удобна, проста в работе, дружелюбна даже для далеких от техники людей.
Есть специальные модули, отвечающие за нестандартные типы информации, например, поиск по торрентам или решение математических задач – о них подробнее я расскажу ниже.
Есть логическая фильтрация запросов, при которой выбирается только та, категория ответов, которая относится к теме. Например, множество фраз имеют двойное, тройное и более значение. Обычный поиск будет показывать все вперемешку, Нигма же, узнает область ваших интересов и удалить не релевантные ответы.
Существенно усиливает поисковые функции факт того, что Нигма учитывает результаты поиска от других поисковиков, может их сравнивать и комбинировать, что позволяет сделать выдачу более качественной.
Давайте поговорим обо всех функциях подробнее.
Обычный – Необычный поиск Нигма
Выше было упомянуто, что в построении выдачи, в том числе, используются данные других поисковиков, что делает ее более качественной и полной, но это далеко не самый интересный элемент.
Синтаксис поисковых запросов – знать не нужно!
В отличие от других поисковых систем Нигма не требует знания синтаксиса поисковых запросов (всевозможные +, кавычки, восклицательные знаки и прочее). Большинство пользователей не знает, как находить точные фразы или исключать слова с помощью специальных символов, поэтому не применяет их при вводе ключевых запросов.
Здесь все реализовано проще. Мы нажимаем над строкой поиска «Расширенный поиск» и в человеку понятной форме задаем подробные условия поиска.
Хотите исключить заведомо лишние слова – пропишите их в поле «без слов». Допустим при поиске информации о львах, по запросу «Лев», можно исключить слово «Толстой» и страницы о великом писателе не будут вам мешать.
Нужна точная фраза – для нее существует специальное поле. Поиск по конкретному сайту – и это не проблема.
В качестве подсказки, приведен пример того, какой синтаксис пришлось бы набирать вручную, если бы не было готовых полей.
Тут же можно задать регион поиска, используемые поисковые системы, язык, предпочитаемую сортировку по дате и еще несколько функций, заранее уточняющих результаты выдачи – и все это без каких-либо специальных знаний.
Фильтрация запросов (кластеризация)
После того, как по своему запросу вы получили результаты, Nigma.ru дает возможность их профильтровать, чтобы убрать заведомо ненужный мусор и сберечь драгоценное время пользователя на просмотр неподходящих страниц.
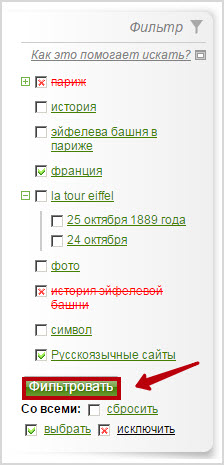
Для этого слева от результатов выдачи появляется список категорий, которые наиболее часто встречаются в полученных результатах. Возвращаясь к примеру со львом, мы видим, что немало сайтов относятся к астрологии, а нам нужны животные – ставим крестики напротив гороскопа. Повторное нажатие на крестик устанавливает галочку – обязательное слово.
Таким способом из всего многообразия страниц с помощью фильтра я оставил только сайты о львах животных и царе зверей.
Поисковые подсказки
В отличие от конкурентов, вводя запрос в строке поиска можно даже не переходить к результатам, так как поисковые подсказки автоматически выдают информацию по вводимому слову из википедии.
Это удобно, если вам встретился незнакомый термин – ввели в строку поиска, навели курсор на подсказку, прочитали ответ. Нажимать Enter необходимости нет.
Выделение официальных сайтов
Удобным для пользователей элементом поиска у Нигмы является подсветка официальных сайтов, к ним в результатах выдачи добавляется специальный значок. С его помощью вы сможете быстро найти нужную организацию среди гор сетевого мусора. Эта фишка помогает защитить интернет от мошенников, так как им не удастся выдать свой сайт за официальный.
Файловый поиск (музыка, книги, торрент)
Не всегда поиск в интернете означает поиск сайтов с информацией, часто пользователи хотят что-то скачать – книги, музыку, torrent файлы с фильмами или программами.
В большинстве случаев обращение за такими данными к Google или Яндекс превращает жизнь в ад, так как результаты выдачи показывают все что угодно, но только не места, где что-то можно скачать.
У поисковой системы Нигма под эти задачи применяются специальные модули, которые работают конкретно под поиск по файлам. Музыка и книги вынесены в специальные вкладки.
Поиск по книгам изначально отбирает сайты, где можно скачать литературу. Поиск по музыке дает ссылки на готовые треки, то есть вы можете прослушать их прямо в браузере или скачать на компьютер. Кстати, зарегистрированные пользователи могут самостоятельно добавлять аудио файлы в систему.
Торрент трекеры в отдельную вкладку не вынесены. Для их поиска Нигма.рф требует ввода в строке поиска дополнительного слова – «торрент» или «torrent». Все найденные торренты с таким названием будет помещены в таблице с указанием количества раздающих и скачивающих пользователей.
Нигма – математика
Это модуль, за который Нигму так полюбили студенты и школьники (и полюбят те, кто первый раз читает статью).
Нигма реально решает задачи по математике – уравнения и примеры различной сложности, включая логарифмы и комплексные числа. Назвать эту функцию поиском сложно, так как ответы не ищутся, а считаются, но фишка реально крутая и необычная.
Причем, выдаются не только результаты решения, но и их ход различными способами.
(Кликните картинку для увеличения)
Принимается к обработке не только числовой ввод данных, но и слова. Можно написать уравнение на русском языке без цифр и система все равно его посчитает (допускаются даже определенные ошибки в словах).
Надеюсь, что эти возможности не будут снижать уровень образования в нашей стране и студенты будут им пользоваться только для проверки.
Нигма – химия
Отдельным разделом химия не выделена, но работает по аналогии с Нигма-математика. В строке поиска вводите словами или буквами вещества, а поисковик покажет все возможные химические реакции между ними, подкрепив формулы подсказками и комментариями.
Мне химия в школе давалась легко, но я знаю, что для многих одноклассников это был такой темный лес, что Нигма-химия может стать единственным выходом из него.
Онлайн конвертер величин и валют
Еще одна фишка – это способность преобразовывать различные величины в другие единицы. Можно попросить перевести единицы измерения информации, например, задав вопрос “сколько мб в 4 гб” получим вот такой ответ:
Возможен пересчет валют разных стран по текущему курсу. Система воспринимает даже некоторые простонародные названия. Достаточно задать вопрос человеческим языком и вы узнаете “сколько зайчиков в 5 деревянных”:
Когда пообщаешься с Nigma плотнее, то начинаешь верить в то, что искусственный интеллект уже реальность.
Нигма для вебмастеров – поиск по сайту
Несмотря на то, что наибольший интерес (на данный момент) интеллектуальная поисковая система представляет для пользователей, все же есть полезности и для вебмастеров.
Речь идет о поиске по сайту. Если вы читали мою статью о том, как сделать Яндекс поиск по сайту (статья тут), то понимаете, о чем идет речь. Если нет, то коротко поясню.
В этом интернет поисковике есть возможность сгенерировать скрипт, который будет осуществлять поиск информации не по всей сети, а только по вашему сайту. Вы ставите этот код с поисковой формой у себя, и пользователи с его помощью могут находить нужные страницы вашего ресурса – особенно полезная штука для информационных сайтов. Преимущество перед стандартным поисковиком от WordPress – релевантный поиск, учет синонимов и прочих фишек современных поисковых алгоритмов.
На одном из моих сайтов он настроен и выглядит вот так:
Как настроить Нигма – поиск по сайту
Перейти к конструктору можно с главной страницы поисковика или по этой ссылке.
- Внешний вид поисковой формы
- Выбор области поиска
Сразу ставится галочка по сайту, можно добавить еще «Интернет», «Изображения», «Музыка».
- Адрес сайта и кодировка
Если не знаете кодировку своего сайта, то откройте его исходный код (клавиши Ctrl+U) и в начале найдите тег meta с атрибутом charset=”кодировка сайта”. Чаще всего бывает Windows-1251 или UTF-8. Если кодировка будет не совпадать, то вместо букв в результатах поиска вы увидите иероглифы.
- Формирование кода формы поиска и страницы вывода результатов
Можно сделать так, чтобы результаты поиска выводились поверх страницы сайта, либо в новом окне, но мне больше нравится вписывать все в дизайн и выдавать все внутри сайта на специальной странице. Для этого выбираем «Во фрейме, на другой странице сайта», прописываем адрес страницы, где выводить данные (эту страницу надо будет создать, как создавать страницы в WordPress смотрите тут).
Получаем 2 кода:
- Код фрейма с результатами поиска вставляем на созданную страницу;
- Код поисковой формы вставляем в то место сайта, где хотим видеть строку для ввода запросов.
Заключение
Лично мне поисковик очень понравился – богатый функционал, возможность быстро найти все что нужно, отсортировать результаты (автоматом исключить заведомо ненужные результаты), приятный дизайн, интуитивно понятный интерфейс. Одним словом – все, что нужно для комфортного поиска рядовому пользователю.
Радует то, что такой мощный программный продукт был создан нашими соотечественниками из МГУ чуть ли не на коленках. Хочется пожелать авторам и владельцам толковых специалистов по маркетингу, которые бы помогли продвинуть его в массы. Я бы с удовольствием отдал Гугловскую долю рынка им.
Интеллектуальная поисковая система Нигма: особенности использования

На фоне Яндекса, Google и Bing, интеллектуальная поисковая система Нигма занимает довольно скромное место. Тем не менее, она не уходит из интернета, а, наоборот, развивается и совершенствуется. Что же находят пользователи в Нигме? Чем она их привлекает? Об этом и пойдет речь в данной заметке.
Приблизительно год назад кириллическая интеллектуальная поисковая система преобразилась и перебралась на новый адрес. Сегодня ее можно найти не только введя в адресную строку «nigma.ru», но и «нигма.рф». У Нигмы есть собственный поисковый робот, но в работе она преимущественно опирается на базы Яндекса, Google, Рамблера, Bing, Yahoo и Altavista. Это значительно расширяет возможности системы и превращает ее в метапоисковик. Под строкой поиска мы можем кликнуть по надписи «Поисковики» и отметить те из них, которые желаем использовать.
Среди других настроек следует отметить возможность выбора языка (имеются опции: русский, украинский, английский или все три), типа сортировки по дате и региона.
Главной изюминкой интеллектуальной поисковой системы Нигма является кластеризация результатов поиска. Она делит их по категориям, с помощью которых пользователю легче найти веб-страницу наиболее точно отвечающую на его запрос (наиболее релевантную). Вводя тот или иной запрос в строку поиска, мы часто не задумываемся о том, насколько он может быть многозначным. В первую очередь это касается одно- и двухсловных запросов.
Например, мы хотим заказать букет и вводим в строку поиска «цветы»:
В левой панели интеллектуальная поисковая система Нигма отображает наиболее вероятные кластеры для данного запроса (сад, дом, сонник, садовые цветы, все о цветах, комнатные цветы, любовь и т.д.). Для уточнения поиска мы теперь вычеркиваем те кластеры (уточняющие слова), которые в наименьшей степени отражают предмет поиска (один клик по квадрату слева от уточняющего слова) или выделяем наиболее подходящие варианты (два клика по квадрату). После этого нажимаем кнопку «Фильтровать» и получаем уточненный результат.
Естественно, нас интересует заказ букета в определенном населенном пункте, например, в Москве. Для этого мы уточняем регион и получаем список необходимых нам ресурсов. К естественной выдаче примешиваются рекламные объявления из Яндекс.Директ, максимально отвечающие нашему запросу. А справа располагается небольшой справочник, в котором мы можем уточнить значения некоторых терминов, содержащих слово «цветы». Используя такой подход мы можем оставить ссылки лишь на те страницы, которые в максимальной степени удовлетворяют предмету поиска. Но этим возможности интеллектуальной поисковой системы не ограничиваются. Нигма (нигма.рф) умеет решать несложные математические задачи, учитывая единицы измерения. При этом она на лету подставляет распространенные физические и математические константы. Кроме того, Nigma может служить калькулятором валют, решать системы уравнений и строить графики функций онлайн.
Интеллектуальность поисковой системы Нигма подтверждает также поддержка расширенного поиска по химическим реакциям (органическая и неорганическая химия). В настоящее время она ведет поиск уравнений более чем по 12 тысячам реакций неорганической химии, как по исходным веществам, так и по продуктам реакции. Причем вещества можно вводить как в виде химических формул, так и в виде названий на русском языке.
Понятно, что математическая и химическая компоненты Нигмы наиболее востребованы у школьников и студентов. Им же пригодится функция обзорного поиска, которая позволяет в сконцентрированном виде получить открытые сведенья из различных областей. Ее удобно использовать при подготовке рефератов. Я думаю, найдутся и такие люди, которые оценят поиск интеллектуальной системы по торрент-трекерам.
Как видите, поисковая система Нигма со многими вещами справляется лучше популярных поисковиков. Поэтому я рекомендую вам добавить ее в свои интернет-закладки.
Раздел 5. Интеллектуальные информационно-поисковые системы
5.1. Интеллектуальные информационно-поисковые системы (ипс). Иипс в сети Интернет
Одним из перспективных направлений применения ИИ в прикладных задачах служит разработка интеллектуальных информационно-поисковых систем (ИИПС). В первую очередь для работы в сети Интернет.
Огромные объемы хранимой информации, разнообразная форма подачи одного и того же материала, различные степени релевантности запросу – все это делает задачу поиска в больших хранилищах данных весьма и весьма актуальной.
Первые системы поиска были достаточно просты. Это был простой поиск подстроки в строке (группы символов в файле), с которым мы сегодня встречаемся, пожалуй, в любом текстовом редакторе. Более развитые средства поиска появились в составе систем управления базами данных, где искать приходилось уже не просто подстроку, а запись с нужными значениями в заданных полях. Появились запросы с логическими связками И, ИЛИ, НЕ, обрабатывающие не только текстовую, но также и числовую информацию. Легко можно представить себе запросы по поиску изображений (например, фото определенного человека в банке фотографий), звуков (поиск мелодии по ее фрагменту) и т.п.
Модели поиска. На сегодня можно выделить несколько подходов к поиску.
1. Поиск по подстроке. Это традиционный поиск подстроки в строке, когда информация считается найденной, если в файле встретилось сочетание символов, в точности соответствующее строке запроса. Далее пользователю предоставляется для просмотра найденное место в файле (обычно текстовом) и он принимает решение об окончании или продолжении поиска. Регистр букв в этом поиске может по желанию пользователя учитываться, а может и нет. Например поиск слова «мыла» во фразе «Мама мыла раму» укажет второе слово. Применяется для поиска информации в отдельном файле или группе файлов на локальном компьютере.
2. Поиск по маске. Это усложненный вариант поиска по подстроке, когда отдельные элементы подстроки заменены специальным символом, указывающим, что в этой позиции может стоять произвольный символ или произвольный символ заданного класса. Например, если знак «*» обозначает произвольный символ запрос фрагмента «*ам» укажет вначале слово «Мама», а затем, если это необходимо, слово «раму». Также применяется на локальных компьютерах.
3. Тематический поиск (на основе классификации). При таком поиске все известные поисковой машине документы разбиваются по иерархизированным каталогам (темам, классам), поддерживающим отношение включения. Классы между собой не пересекаются. Пользователь может делать запрос только по заранее сформулированным ему темам. Поиск на пересечении или объединении классов не предполагается. Не предполагается и упорядочение документов (кроме естественного в порядке обнаружения). Подобный поиск был популярен на ранних этапах развития Интернет. В настоящее время он играет лишь вспомогательную роль (вроде ссылок на тематические рубрики «товары», «спорт», «фото» и т.д. на интернет-порталах типа mail.ru, rambler.ru и им подобных).
4. Булева модель. Запрос представляет собой высказывание, возможно с пропозициональными связками И, ИЛИ, НЕ. Пользователю предлагаются информационные единицы, для которых это высказывание истинно. Связки могут обозначаться специальным образом, например «.OR.» для ИЛИ, .AND. для И и .NOT. для НЕ, или подразумеваться. Например подряд идущие слова в запросе «книги фото товары» интерпретируется как конъюнкция «книги.AND.фото.AND.товары». Такой метод широко применяется в системах управления базами данных. Он позволяет осуществлять поиск на пересечении, объединении и теретико-множественном вычитании классов.
5. Поиск по ключевым словам. Документ описываются набором ключевых слов. При наличии их в запросе соответствующий документ предоставляется пользователю. Запрос представляет собой набор ключевых слов с пропозициональными связками. Один из наиболее старых, но до сих пор эффективных подходов к поиску в больших объемах информации.
6. Векторная модель. Документы и запросы характеризуются системой атрибутов, которые имеют веса и представляются в виде векторов. Далее степень соответствия документа запросу оценивается по степени близости соответствующих векторов друг другу.
7. Интерактивный поиск. Развитие векторной модели. В процессе поиска учитывается, какие из предложенных документов заинтересовали пользователя. После этого поисковая машина корректирует критерии и продолжает поиск.
Не все перечисленные модели применяются для работы в Интернет. Рассмотрим те, что используются.
Поиск на основе классификации. Общая схема поисковой машины представлена на рис. 3.18.

Поиск осуществляют люди, либо специальные программы-сканеры Интернета. Кроме того, возможна процедура регистрации докуменотов (сайтов) в поисковой системе самими владельцами документов.
Данная система малоэффективна при большом количестве документов: разрастается число классов, трудно поддерживать базы в актуальном состоянии. Ограничиваются и возможности составления запросов для пользователей.
Поиск по ключевым словам (наиболее распространенный). Схема работы поисковой системы представлена на рис. 3.19. Основными этапами ее работы являются:
1. Поиск документов индексирующим роботом.
2. Индексирование найденных документов.
3. Выполнение запросов пользователя.

По результатам работы индексирующего робота пополняются и корректируются база ссылок на документы и база поисковых образов документов. Базы индексируются по ключевым словам. По запросу пользователя выполняется обращение к базе индексов, которая и предлагает ему список документов.
Недостатки:
1. Слабая степень релевантности документов запросу.
2. Индексирующие роботы сильно загружают сеть.
3. Трудно поддерживать базы в актуальном состоянии.
4. Малый охват объемов Интернет (по некоторым оценкам крупная поисковая система охватывает не более 16% выложенной информации, использование 11 поисковых систем позволяет охватить до 42% менее половины).
5. Возможность обмана для повышения рейтинга «паразитных» сайтов.
6. Большое количество документов, выдаваемых по запросу.
7. Наличие ссылок на отсутствующие документы.
Впрочем, это проблемы едва ли не всех современных поисковых систем. Перспективным направлением здесь может служить применение методов ИИ. Работу интеллектуальной (точное «интеллектуализированной») системы поиска информации можно представить в следующем виде (рис. 3.20).

Первые три позиции здесь характерных для современных поисковых машин. Последняя делает ее интеллектуализированной.
Лексический анализ заключатся в разборе текстовой информации на отдельные абзацы, предложения, слова, определении национального языка изложения, типа предложения, выявлении типа лексических выражений (бранных, жаргонных слов) и т.д. Он не представляет существенной сложности для реализации.
Морфологический анализ сводится к автоматическому распознаванию частей речи каждого слова текста (каждому слову ставится в соответствие лексико-грамматический класс). Качество морфологического анализа сильно зависит от языка. Например в русском языке, где развита морфология это можно сделать практически со стопроцентной точностью. Английский язык более многозначен и качество работы соответствующего анализатора оценивается в пределах девяноста процентов.
Синтаксический анализ заключатся в автоматическом выделении семантических элементов предложения — именных групп, терминологических целых, предикативных основ. Это позволяет повысить интеллектуальность процесса обработки тестовой информации на основе обеспечения работы с более обобщенными семантическими элементами.
Семантический анализ заключатся в определении информативности текстовой информации и выделении информационно-логической основы текста. Проведение автоматизированного семантического анализа текста предполагает решение задачи выявления и оценки смыслового содержания текста. Данная задача является трудно формализуемой вследствие необходимости создания совершенного аппарата экспертной оценки качества информации. Именно семантический анализ текста – основа интеллектуальности ИПС.
Реализация семантического анализа текстовой информации предполагает обязательное использование экспертных систем, систем искусственного интеллекта для выявления смыслового содержания информации. В настоящее время отсутствуют сложившиеся подходы к реализации задачи семантического анализа текстовой информации, что во многом обусловлено исключительной сложностью проблемы и недостаточно полной проработкой научного направления создания систем искусственного интеллекта. Поэтому существующие информационные технологии не обеспечивают эффективной реализации поисковых систем. Это обусловливает низкую адекватность найденной по запросу пользователя информации, то есть возврат системой большого объема малоинформативных документов. Проблема усугубляется низкой скоростью получения документов из Интернета, необходимостью просмотра пользователем всех найденных документов и оценки их информационного содержания в неавтоматизированном режиме, а также наличием специально создаваемых (вредоносных) информационных технологий, препятствующих эффективной реализации в поисковых системах автоматической оценки содержания найденных документов.
Методический аппарат «интеллектуального поиска» текстовой информации позволяет реализовать автоматизацию всех этапов лингвистического анализа (лексического, морфологического, синтаксического и семантического). Данная технология соединяет преимущества автоматического индексирования документов в поисковых системах с экспертной обработкой их содержания в системах искусственного интеллекта.
Реализация указанных функциональных возможностей достигается за счет:
углубленного лексического анализа текстовой информации, обеспечивающего подготовительную нормализацию обрабатываемого теста;
наличия морфологического словаря, включающего все морфологические и семантические характеристики слов, а также слова-синонимы и тематически связанные слова;
детального морфологического анализа, обеспечивающего определение частей речи с учетом семантики запроса пользователя и обрабатываемой текстовой информации;
поиска текстовой информации по синонимам и тематически связанным словам;
автоматизированного синтаксического анализа членов предложения и связей между ними;
отбора текстовой информации на основе семантического анализа ее соответствия запросу пользователя;
автоматической оценки релевантности предложений текстов запросу пользователя с обеспечением синтеза семантически полного ответа поисковой системы.
Считается, что интеллектуализированная ИПС будет должна следующими качествами:
обрабатывать запросы пользователя на естественном языке;
реализовывать диалог с пользователем в ходе уточнения введенного им запроса и формирования ответа системы;
автоматически переводить запрос пользователя с естественного языка на формализованные языки запросов поисковой системы;
обеспечивать поиск с учетом смыслового содержания многозначных слов;
учитывать синонимы и тематически связанные слова.
учитывать семантики запроса и синтезировать семантически полные ответы поисковой системы.
оценивать семантическую релевантность запросы найденным результатам.
Архитектура такой системы может выглядеть следующим образом (рис. 3.21):

В рунете запущена новая интеллектуальная поисковая система
Интернет Веб-сервисыИнтеллектуальная поисковая система Nigma.ru, результат работы студентов и аспирантов факультетов ВМиК и психологии МГУ им.М. В. Ломоносова, официально запущена в статусе альфа-версии.
Членами команды разработаны оригинальные алгоритмы ранжирования результатов, полученных от набора поисковых систем, с поддержкой русской морфологии и двухуровневой кластеризации. Морфология реализована через отсылку в поисковые системы дублирующих запросов, в которых приведены распространенные морфологические формы запрашиваемых слов. При этом, в отличие от имеющихся реализаций русской морфологии для поисковых систем, предлагаемый алгоритм не сокращает, а увеличивает количество найденных документов, т.к. морфологически измененный запрос объединяется с исходным. Релевантность также увеличивается, т.к. используются специальные алгоритмы объединения результатов. Позиция найденной ссылки в результатах поиска отображается в виде «Поисковая система: позиция» (например, Google: 5 означает, что ссылка находится на пятом месте в поисковой системе Google), а ссылки от морфологически измененных запросов в виде «Поисковая система-M: позиция» (например, Google-M: 10 десятая ссылка в морфологически измененном запросе).
Результаты поиска объединяются с помощью специального алгоритма, причем только те результаты, которые Nigma.ru успевает получить от поисковых систем за 1,5 секунды (в очень редких случаях за 5 секунд). Соответственно, алгоритм не выделяет какие-то поисковые системы таким образом, что результаты поиска от них имеют большую значимость, чем от других, т.к. нет гарантии, что за это время система успеет обработать эти результаты. Вместо этого для их объединения используется статистическая информация о русскоязычном интернете, такая как посещаемость (на базе публичных счетчиков) и цитируемость сайтов. Кроме того, учитываются другие специфичные для рунета и русского языка особенности при объединении результатов.
В итоге, по утверждению разработчиков, на подавляющее большинство поисковых запросов Nigma.ru выдает на порядок больше найденных сайтов, чем, например, при простом поиске на сайте Google.ru. Для того чтобы пользователь не запутался в этих результатах, они группируются в так называемые кластеры. Каждый кластер это группа сайтов, относящихся, по «мнению» поисковой системы, к общей тематике. Разработчики решили использовать частотную кластеризацию по ключевым словам, поэтому названия кластеров это тоже ключевые слова, которые пользователь может применять для расширения своего запроса. В свою очередь, т.к. количество найденных кластеров также часто очень велико, интеллектуальный алгоритм объединяет кластеры в иерархию (пока двухуровневую), которая позволяет представить их в более компактном виде. Например, введя очень общий запрос «новости», на который поисковая система Nigma.ru выдает порядка полумиллиарда документов, в левой колонке можно увидеть самые популярные темы новостей, которые встречаются в интернете. Нажав на тему (например, «спорт»), вы получите примеры новостных ресурсов, которые освещают эту тему. Если Вы хотите получить больше ресурсов о новостях спорта, нужно нажать на «Расширить запрос» тогда система выдаст более двух миллионов ссылок о новостях спорта. Они, в свою очередь, тоже отклассифицированы по темам футбол, хоккей и т.п.
Участники исследовательской группы планируют продолжить разработку кластеризующих алгоритмов. В ближайшее время поисковая система будет расширена экспертными системами, психологическими тестами, системами поведенческого анализа и другими методами, базирующимися на таких алгоритмах искусственного интеллекта как искусственные нейронные сети, генетические алгоритмы, алгоритмы нечеткой логики и т.п. После того как будет создана стабильная версия кода, планируется опубликовать его исходные тексты.
Интеллектуальные поисковые системы
Тенденция к информационному самообслуживанию повышает релевантность полных приложений по сравнению с инструментами
В ходе бесед с клиентами мы заметили тенденцию, которая существенно влияет на то, как семантические решения вписываются в корпоративный ландшафт. В «старые добрые времена» сотрудник с вопросом отправлял его внутренней группе информационных экспертов, которые использовали набор экспертных инструментов для ответа (в виде отчета или списка обратной связи) первоначальному запросившему.
Хотя это все еще распространено во многих местах, мы замечаем тенденцию все больше и больше полагаться на решения самообслуживания , которые ставят сотрудника в положение конечного пользователя , получая доступ к решениям, которые пытаются ответить на большую часть входящих вопросов с помощью веб-решения. Добро пожаловать в мир интеллектуальной поисковой системы .
Здесь играет роль ряд факторов. Все больше и больше пользователей чувствуют себя уверенно, выполняя поиск самостоятельно .Вдохновленные (часто вводящим в заблуждение) впечатлением, что, поскольку они знают, как использовать свою любимую поисковую систему, они думают, что тот же тип поиска также эффективен на профессиональном уровне. Вместо того, чтобы консультироваться с внутренней командой экспертов, средний пользователь просто пошел бы вперед и поискал себя.
В то же время решений, обеспечивающих быстрый доступ к актуальной информации, т.е. Интеллектуальные поисковые системы — становятся все более мощными и интуитивно понятными . Наконец, бюджеты информационных отделов ограничены и часто пересматриваются.
В результате все больше и больше пользователей, которые являются экспертами в своей конкретной области — например, биологии, юриспруденции или инженерии — , оказываются напрямую открытыми для интерфейсов поиска и анализа без обнадеживающего присутствия специалиста по информации, который мог бы помочь или улучшить опыт. Это возлагает большую ответственность за производительность на технологические решения и инструменты. Хотя для частных пользователей может быть приемлемо заниматься поиском без более детального понимания принципов, лежащих в основе поисковой машины [1], в корпоративной среде это не так. В корпоративной среде, где неполные или ошибочные результаты поиска могут иметь гораздо большее влияние, необходимость иметь соответствующие инструменты, конечно, намного выше.
Как сказал один из спонсоров проекта: «Цель решения, которое мы хотим, — не сделать 5% наших сотрудников на 100% умнее, а сделать 80% наших сотрудников на 10% умнее». В конце концов, многие пользователи даже не используют логический поиск. В результате они не смогут оценить весь потенциал индексации на основе тезауруса или более совершенных технологий, которые доступны для повышения эффективности поиска.
Прочтите также статью о системах обработки естественного языка в искусственном интеллекте.
Интеллектуальные поисковые системы в Экспертной системе
В Expert System мы переводим это в , увеличивая усилия по разработке не только основного механизма обработки информации, но и всего приложения . Мы знаем, что должны уметь учитывать тот факт, что интуитивно понятные интерфейсы и эффективная обработка документов, как правило, скрывают сложности того, что происходит «под капотом», когда дело доходит до интеллектуальной поисковой системы .
Наш Biopharma Navigator — прекрасный пример такого подхода . Информация, к которой необходим доступ профессионалов в области наук о жизни и фармацевтики, слишком сложна, неоднородна и распределена, чтобы ее можно было быстро усвоить без помощи профессиональных информационных специалистов и интеллектуальных поисковых технологий.
Biopharma Navigator — это веб-решение, которое позволяет экспертам в предметной области, не являющимся специалистами в области информации, проводить набор типичных сценариев, таких как поиск экспертов, новости о терапевтической области или деятельность конкурентов .Результаты, обогащенные типичными синонимами за сценой, представлены на многофункциональных панелях мониторинга, которые обеспечивают немедленный доступ к информации, которую они ищут.
 Рис. 1. Навигатор Biopharma Navigator предоставляет пользователям быстрый и интуитивно понятный доступ к более чем 40 миллионам документов.
Рис. 1. Навигатор Biopharma Navigator предоставляет пользователям быстрый и интуитивно понятный доступ к более чем 40 миллионам документов.
Сегодня нашим Biopharma Navigator профессионально пользуются более 1000 отраслевых экспертов , чтобы быстро и легко получить доступ к необходимой информации.
В аналогичном ключе наша программа Analysts ’Workspace реализует ту же идею: Передает мощных семантических технологий в руки людей, которым нужны быстрых и всеобъемлющих результатов (без необходимости начинать с нуля для каждого нового поиска).
Не каждый может быть экспертом в анализе текста : Некоторым из нас необходимо уметь лечить рак, принимать правильные инвестиционные решения или оценивать политические риски и возможности, оставляя анализ необходимых источников на усмотрение экспертов.Это наша миссия в Expert System.
Стефан Гейсслер
Старший научный сотрудник, экспертная система
[1] Vgl. http://www.blogs.uni-mainz.de/ifp/files/2013/08/Suchmaschinen_Management_Summary.pdf
,Интеллектуальный поиск | Yext
С учетом того, что 77% взрослого населения США владеют смартфонами, а прогноз, что голосовой поиск будет составлять 50% всего поиска к 2020 году, ясно указывает на то, что ландшафт поиска быстро меняется. Компании должны учитывать это и готовиться к следующей волне сбоев: интеллектуальный поиск .
Поиск больше не может определяться ключевыми словами и 10 синими ссылками на странице результатов поисковой системы. Интеллектуальные системы, такие как карта знаний Google и Amazon Alexa, теперь предоставляют единые и прямые ответы о вашей компании поисковым потребителям.Например, если потребитель ищет новый автомобиль, ему теперь предоставляется карточка знаний, в которой содержится такая информация, как цены, конфигурации и характеристики. Точно так же, если кто-то ищет продукты или банки, результат поиска возвращает карты, поскольку теперь Google предполагает, что люди ищут место, если они ищут что-то, присутствующее в физическом мире.
Благодаря увеличению использования голосовых и подключенных устройств более чем на 130% с 2016 по 2017, интеллектуальный поиск — это не то, что компании могут игнорировать.Интеллектуальный поиск — это новая сеть систем, дающих прямые ответы. Примерами интеллектуальных поисковых систем являются голосовой поиск, например Siri от Apple или Alexa от Amazon, карта знаний Google, искусственный интеллект и машинное обучение. Search Engine Land недавно сообщил, что каждый четвертый поисковый запрос Google дает карту знаний. Это означает, что 25% всех поисковых запросов Google дают разумные ответы. Это также означает, что пользователи с большей вероятностью будут полагаться на эти интеллектуальные результаты, а не переходить на веб-сайт компании, чтобы найти информацию о компании или местоположении.Недавнее исследование Yext Analytics показало, что обычные онлайн-списки привлекают в 2,7 раза больше внимания на картах, в социальных сетях, поисковых системах и приложениях, чем на их собственных сайтах. Эти новые механизмы продолжают развиваться и изменять способ взаимодействия потребителей с результатами поиска, а также с брендами.
Интеллектуальный поиск может только набирать обороты, но скоро ваш бренд будет жить и в других интеллектуальных системах, таких как беспилотные автомобили от Uber и Tesla, а позже и в технологиях, таких как дроны, датчики, виртуальная реальность и умная одежда. ,Появление интеллектуального поиска и интеллектуальных систем создало и будет создавать беспрецедентный уровень потребности в управлении цифровыми знаниями. Вы можете только представить себе, какую головную боль это вызовет у ваших клиентов, если ответы, данные им этими системами о вашей компании, будут неправильными, и, что еще хуже, эти неточные цифровые знания плохо отразятся на вашей компании, а не на поисковой системе. Потребители теперь полагаются на интеллектуальные услуги, чтобы обеспечить им соответствующие результаты в цифровой экосистеме.По мере развития поисковой среды веб-сайт бренда становится менее важным для потребителей, которые становятся более мобильными и требуют немедленных ответов.
В то время как расширенный контент имеет решающее значение для SEO, структурированные данные еще более важны для интеллектуального поиска. Структурированные данные — это высокоорганизованная информация, которая хранится в фиксированных полях и включает такие вещи, как атрибуты бизнеса и категории, такие как варианты без глютена. Эти интеллектуальные ответы часто основываются на фрагментах детализированных данных; Таким образом, структурированные данные становятся еще более важными для работы вашего бренда в поисковой сети.Структурированные данные позволяют поисковым системам и интеллектуальным поисковым службам определять, соответствуют ли цифровые знания вашей компании каждому запросу. Чем более структурированные данные вы сможете предоставить, тем более заметным будет ваш бренд в интеллектуальных ответах. Например, если вы спросите Siri «, что такое надгробие?» она откроет определение из Википедии, показывающее изображения и описание надгробий, но если вы спросите ее: «, где находится надгробие ?» Она открывает карту, указывающую на город Надгробие в Аризоне.По мере того, как поиск становится все более интеллектуальным, интеллектуальные службы получают структурированные данные и используют ИИ для интерпретации того, что вы ищете. Чтобы получать разумные ответы, ваша компания должна предоставлять структурированные данные, которые соответствуют поисковым запросам ваших клиентов.
Какими бы умными ни были интеллектуальные сервисы, они хороши ровно настолько, насколько хороши данные, которые вы вводите. Повысьте эффективность интеллектуального поиска, изучив долю вашего бизнеса в интеллектуальном поиске и положение по сравнению с конкурентами с помощью интеллектуального поискового трекера Yext.Intelligent Search Tracker, запатентованный Yext подход к отслеживанию рейтинга, позволяет вам оценить ваше истинное влияние в сегодняшней новой эпохе. Интеллектуальный поисковый трекер Yext позволяет измерять не только ваш рейтинг в результатах поиска, но и ваш контроль над данными, которые потребители видят в результатах поиска. Интеллектуальный поисковый трекер позволяет вам отслеживать до семи ключевых слов, каждое по четырем шаблонам запросов, на основе данных, которые вы храните в Yext Knowledge Manager, таких как ваше имя и категория.Или создайте собственные ключевые слова, которые представляют трафик, который вы хотите привлечь. Затем измерьте свою эффективность по нескольким показателям.
Интеллектуальный поисковый трекер поможет вам понять, как ваша компания работает в интеллектуальном поиске. Щелкните здесь, чтобы узнать больше об этой функции в блоге Yext. Вы также можете узнать больше о показателях интеллектуального поискового трекера Yext Analytics. Чтобы узнать больше о структурированных данных в развивающейся среде интеллектуального поиска, ознакомьтесь с нашей электронной книгой.
,Bing представляет новые функции интеллектуального поиска на базе искусственного интеллекта

Вчера на мероприятии Microsoft по ИИ в Сан-Франциско компания продемонстрировала свое видение вычислений на базе ИИ, а также стратегию дифференциации ИИ. Последнее, по сути, сводится к трем большим идеям: сделать программное обеспечение с поддержкой ИИ широко доступным для людей для улучшения «повседневного» опыта, бесшовное сочетание рабочих и личных функций в одних и тех же инструментах и стремление стать этичной компанией ИИ.
Microsoft показала, как искусственный интеллект и машинное обучение теперь поддерживают ее основные продукты, от Windows до Office 365 и Bing. Самая впечатляющая демонстрация дня (с точки зрения личного интереса) включала в себя автоматизированные предложения дизайна в PowerPoint, управляемые ИИ.
Было несколько объявлений об ИИ, ориентированных на Bing, все под заголовком «интеллектуальный поиск»:
- Интеллектуальные ответы
- Интеллектуальный поиск изображений
- Разговорный поиск
Интеллектуальные ответы
Считайте это своего рода «избранными фрагментами нового поколения».Но что отличается и интересно, так это то, что Bing часто обобщает или сравнивает несколько источников информации, а не просто представляет один ответ.
Если, например, существуют конкурирующие точки зрения по проблеме, Bing их представит. Это также обеспечит «карусель разумных ответов», если на вопрос есть несколько ответов. Это сделано для того, чтобы заменить «синие ссылки» и обеспечить быстрый доступ к соответствующей информации.
Ниже представлен предоставленный Bing пример сравнения двух разных источников контента по вопросу «Полезна ли капуста для вас?»

Интеллектуальный поиск изображений
Здесь Bing, по сути, делает то, что Pinterest объявила в 2016 году, с «визуальным поиском» и распознаванием объектов.Bing стремится сделать практически любое изображение доступным для покупок. Сейчас эта возможность сосредоточена на моде и домашней мебели.
Пользователи могут «щелкнуть значок увеличительного стекла в правом верхнем углу любого изображения, чтобы выполнить поиск по изображению и найти связанные изображения или продукты». Пример ниже показывает, как это работает.


Bing также может обнаруживать и идентифицировать здания и ориентиры на фотографиях пользователей или в поиске изображений, но пока еще не в реальном мире.
Google Lens предлагает визуальный поиск объектов и мест в реальном мире (как и Amazon для продуктов).Я ожидал, что скоро Bing представит аналогичную возможность Lens через Cortana или свое приложение для поиска.
Разговорный поиск
Bing выводит предложения / автозаполнение при поиске на новый уровень с помощью того, что он называет «диалоговым поиском». В случае очень общего или неопределенного запроса Bing поможет с предложениями по уточнению запроса:
Теперь, если вам нужна помощь в определении правильного вопроса, Bing поможет вам с уточняющими вопросами на основе вашего запроса, чтобы лучше уточнить ваш поиск и получить лучший ответ с первого раза.Вы начнете замечать этот опыт в вопросах здоровья, технологий и спорта, и со временем мы будем добавлять новые тематические области. А поскольку мы создали его с помощью крупномасштабного машинного обучения, со временем он станет лучше по мере того, как с ним будут взаимодействовать все больше пользователей.

Наконец, компания также объявила об интеграции контента Reddit (ответы / мнения) в Bing. Тим Петерсон вчера более подробно писал об этом. Вкратце, однако, Bing будет показывать фрагменты контента Reddit или разговоров, если считает, что это лучший источник информации.
Microsoft также будет продвигать AMA в результатах поиска и на панелях знаний: «В Bing вы можете обнаруживать расписания AMA и просматривать снимки AMA, которые уже были завершены. Просто выполните поиск по имени человека, чтобы увидеть его снимок AMA, или введите запрос «Reddit AMA», чтобы увидеть карусель популярных AMA ».
Маловероятно, что какое-либо из этих изменений изменит положение дел на рынке в краткосрочной перспективе. Однако в совокупности они демонстрируют ускорение изменений в поиске в целом с помощью ИИ.Google, вероятно, будет вынужден ответить на пару новых функций Microsoft.
Если Microsoft действительно хочет привлечь больше пользователей, она должна быть еще более смелой с функциями, контентом и изменениями пользовательского интерфейса. И у компании достаточно сильные позиции для подрывной деятельности, поскольку она не полагается на доходы от поисковой рекламы в той мере, в какой это делает Google.
Об авторе
 Грег Стерлинг (Greg Sterling) — старший редактор Search Engine Land, член команды программистов для мероприятий SMX и вице-президент по анализу рынка в Uberall.,
Грег Стерлинг (Greg Sterling) — старший редактор Search Engine Land, член команды программистов для мероприятий SMX и вице-президент по анализу рынка в Uberall.,